")

共计 3127 个字符,预计需要花费 8 分钟才能阅读完成。
问题描述:
MySQL 基于 keepalived 实现主备切换,业务 A 和业务 B(其实 A 和 B 上跑的业务是相同的)同时使用 MySQL 做数据库查询。通过重启 keepalived 服务来测试 MySQL 主备切换后,能够为业务提供正常的服务。
问题现象 :
测试人员发现 MySQL 主从切换之后,与业务 A 相关的 TCP 连接信息已经变更为新 TCP 连接,而与业务 B 相关的 TCP 连接信息仍旧未变化。
推荐阅读:
Haproxy+Keepalived 搭建 Weblogic 高可用负载均衡集群 http://www.linuxidc.com/Linux/2013-09/89732.htm
Keepalived+HAProxy 配置高可用负载均衡 http://www.linuxidc.com/Linux/2012-03/56748.htm
CentOS 6.3 下 Haproxy+Keepalived+Apache 配置笔记 http://www.linuxidc.com/Linux/2013-06/85598.htm
Haproxy + KeepAlived 实现 WEB 群集 on CentOS 6 http://www.linuxidc.com/Linux/2012-03/55672.htm
Haproxy+Keepalived 构建高可用负载均衡 http://www.linuxidc.com/Linux/2012-03/55880.htm
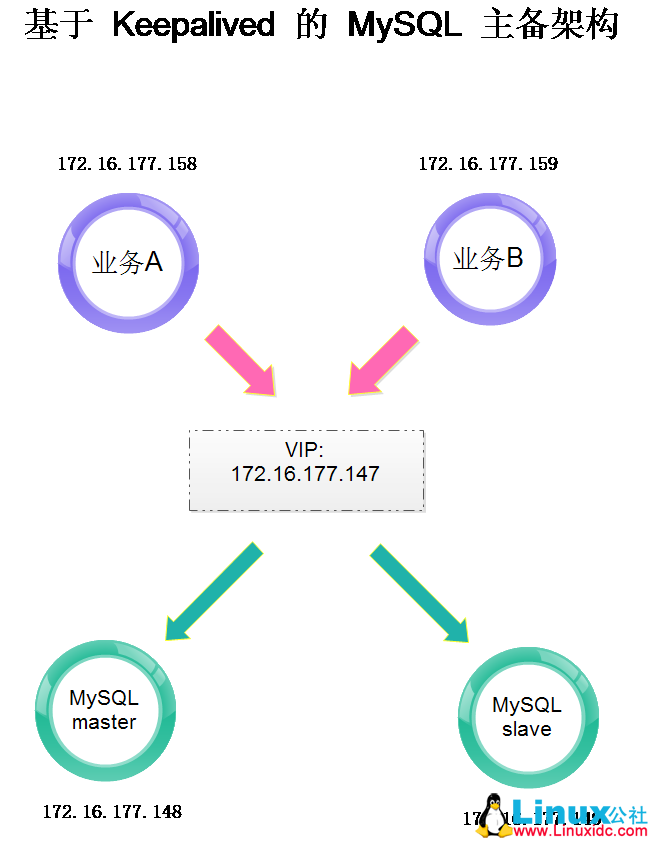
具体环境如下 :
业务 A:172.16.177.158
业务 B:172.16.177.159
VIP:172.16.177.147
MySQL master:172.16.177.148
MySQL slave:172.16.177.149
在业务正常运行状态下,业务 A 通过 VIP 与 MySQL master(148)建立 6 条 TCP 连接(业务开发人员告知的),分别对应端口
43666、43668、43669、43670、43673、43674。
当通过重启 148 机器上的 keepalived 服务来完成 VIP 切换,从而达成 MySQL 主备切换时,可以看到如下抓包信息:
如下为 158 上的 TCP 链接信息。

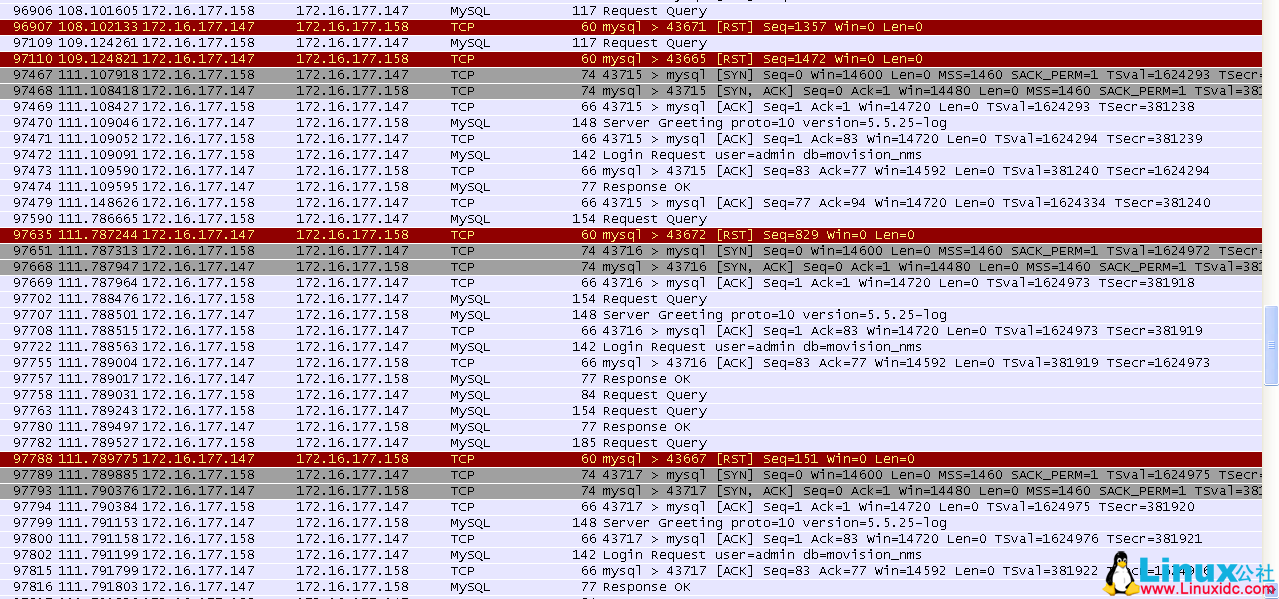
可以看到,上面出现了 10 个 RST ……,呃,先不管为什么多出来 4 个吧。
下面看一下 148(原 MySQL master)上来自 158 的连接信息。
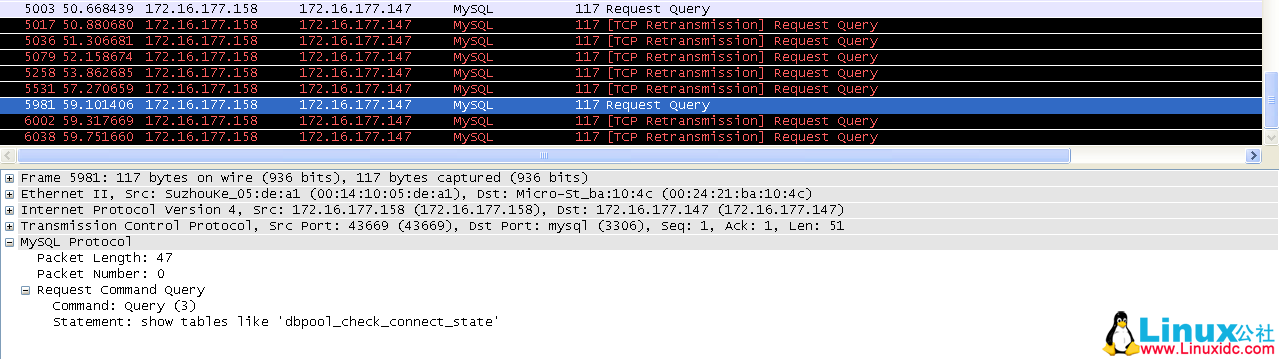
从上面两个截图中,只能看到有两条 TCP 链路上出现了新的请求,并且因为重启了 keepalived 的原因,出现了 TCP 的重发。这两条 TCP 链路对应的端口分别为:43673、43669。
这里重发请求的端口与 158 上的抓包中显示的一致。
再看一下 149(原 MySQL slave)上来自 158 的连接信息。

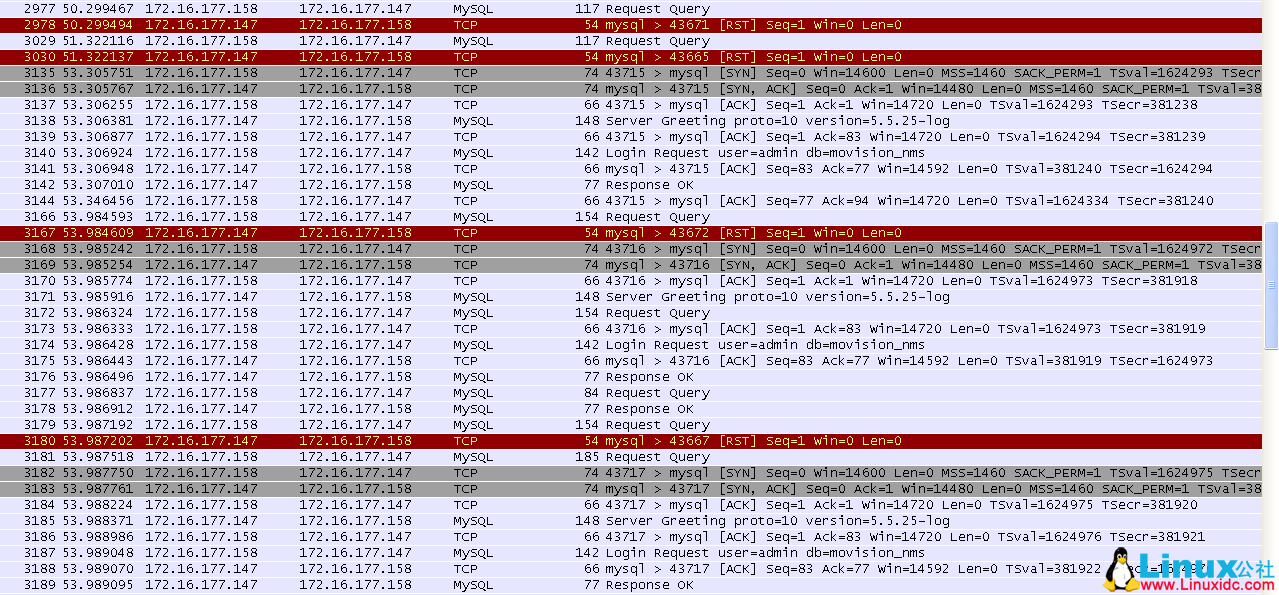
可以看到这里也出现了 10 条 TCP 链路被 RST。与上面的 10 条 TCP 链接是对应的。
更多详情见请继续阅读下一页的精彩内容:http://www.linuxidc.com/Linux/2014-04/100471p2.htm
综上,整个过程可以描述为:
- 最开始 158 与 148 建立了 6 条 OCS 业务的 TCP 连接;
- 在重启 keepalived 的时候,恰好使用端口 43673 和 43669 的 TCP 连接正在信令交互,而此时正处于 VIP 147 从 148 向 149 漂移的过程之中,此时这两条 TCP 链路上的请求会因为得不到任何回应而触发重传;
- 当 VIP 成功绑定到 149 上后,上述两条 TCP 链路上的重传请求会被 RST,而当其他 TCP 链路上有新的请求时,才会被 RST。被 RST 后,OSC 会重新建立 TCP 连接。
下面单独看下每条 TCP 链路的状况:
端口 43673 的 TCP 链路。

端口为 43669 的 TCP 链路。
端口为 43666 的 TCP 链路。
端口为 43674 的 TCP 链路。
端口为 43670 的 TCP 链路。
端口为 43668 的 TCP 链路。
端口为 43671 的 TCP 链路。
端口为 43665 的 TCP 链路。
端口为 43672 的 TCP 链路。
端口为 43667 的 TCP 链路。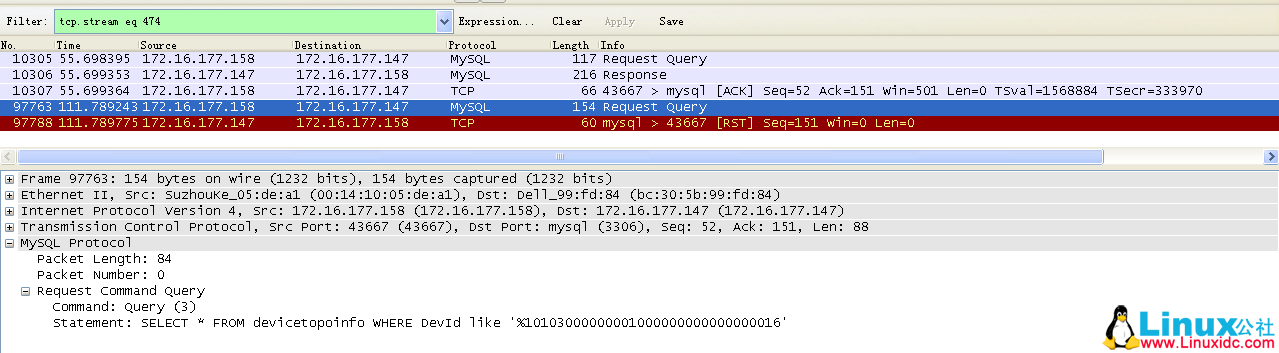
上述现象在对于 159 上的业务来说也是这样,不再重复说明。
总结:
上述问题的出现值得思考的地方有,通过重启 keepalived 来促使 MySQ 主备切换这种方式对于实际应用场景是否有意义?!如果实际情况中真的出现类似于 keepalived 重启导致的 MySQL 主从切换,那么由此导致的主从不一致将如何解决?!业务程序通过某种保活机制出发对当前 TCP 链路是否处于“半打开”状态的检测时间间隔多少比较合适?MySQL 上的 wait_timeout 设置多少比较合适!?
真正让人感到不安的是,仅通过重启 keepalived 来进行主备切换,无论是 MySQL 侧还是业务侧,居然都不会收到 TCP 的 FIN 或 RST,而只会在业务层面有“动作”时才能发现 TCP 链路的问题,这种现象对类似 MySQL 这种服务来说必然会造成一些问题。
问题描述:
MySQL 基于 keepalived 实现主备切换,业务 A 和业务 B(其实 A 和 B 上跑的业务是相同的)同时使用 MySQL 做数据库查询。通过重启 keepalived 服务来测试 MySQL 主备切换后,能够为业务提供正常的服务。
问题现象 :
测试人员发现 MySQL 主从切换之后,与业务 A 相关的 TCP 连接信息已经变更为新 TCP 连接,而与业务 B 相关的 TCP 连接信息仍旧未变化。
推荐阅读:
Haproxy+Keepalived 搭建 Weblogic 高可用负载均衡集群 http://www.linuxidc.com/Linux/2013-09/89732.htm
Keepalived+HAProxy 配置高可用负载均衡 http://www.linuxidc.com/Linux/2012-03/56748.htm
CentOS 6.3 下 Haproxy+Keepalived+Apache 配置笔记 http://www.linuxidc.com/Linux/2013-06/85598.htm
Haproxy + KeepAlived 实现 WEB 群集 on CentOS 6 http://www.linuxidc.com/Linux/2012-03/55672.htm
Haproxy+Keepalived 构建高可用负载均衡 http://www.linuxidc.com/Linux/2012-03/55880.htm
具体环境如下 :
业务 A:172.16.177.158
业务 B:172.16.177.159
VIP:172.16.177.147
MySQL master:172.16.177.148
MySQL slave:172.16.177.149
在业务正常运行状态下,业务 A 通过 VIP 与 MySQL master(148)建立 6 条 TCP 连接(业务开发人员告知的),分别对应端口
43666、43668、43669、43670、43673、43674。
当通过重启 148 机器上的 keepalived 服务来完成 VIP 切换,从而达成 MySQL 主备切换时,可以看到如下抓包信息:
如下为 158 上的 TCP 链接信息。
可以看到,上面出现了 10 个 RST ……,呃,先不管为什么多出来 4 个吧。
下面看一下 148(原 MySQL master)上来自 158 的连接信息。
从上面两个截图中,只能看到有两条 TCP 链路上出现了新的请求,并且因为重启了 keepalived 的原因,出现了 TCP 的重发。这两条 TCP 链路对应的端口分别为:43673、43669。
这里重发请求的端口与 158 上的抓包中显示的一致。
再看一下 149(原 MySQL slave)上来自 158 的连接信息。
可以看到这里也出现了 10 条 TCP 链路被 RST。与上面的 10 条 TCP 链接是对应的。
更多详情见请继续阅读下一页的精彩内容:http://www.linuxidc.com/Linux/2014-04/100471p2.htm














