")

共计 3704 个字符,预计需要花费 10 分钟才能阅读完成。
一.环境准备
1. VMware workstation 9
2. Red Hat linux 6.4版本 32bit
3. JDK版本 jdk-7u45-linux-i586
4. Hadoop jar包 1.2.1 版本 32 位
5. 远程登录及 ftp 工具 ( 自选)
备注:
hadoop安装包下载下载地址:hadoop.apache.org
目前最新版本已经更新到 2.2.0 发布版本
二.部署安装步骤
整体分为:
(1)系统安装
(2)JDK安装及创建 SSH 无密码访问通讯连接
(3)Hadoop解压安装配置
(4)配置网络域名解析及关闭放火墙
2.1 安装系统。
安装好虚拟机后,安装 linux 系统,注意网络连接方式选择桥接 ,其他配置根据个人机器情况自行配置。完全分布式共需要准备3 个虚拟机。
————————————– 分割线 ————————————–
Ubuntu 13.04 上搭建 Hadoop 环境 http://www.linuxidc.com/Linux/2013-06/86106.htm
Ubuntu 12.10 +Hadoop 1.2.1 版本集群配置 http://www.linuxidc.com/Linux/2013-09/90600.htm
Ubuntu 上搭建 Hadoop 环境(单机模式 + 伪分布模式)http://www.linuxidc.com/Linux/2013-01/77681.htm
Ubuntu 下 Hadoop 环境的配置 http://www.linuxidc.com/Linux/2012-11/74539.htm
单机版搭建 Hadoop 环境图文教程详解 http://www.linuxidc.com/Linux/2012-02/53927.htm
————————————– 分割线 ————————————–
我设置的实验虚拟机内存为 512M 硬盘为10G:
节点 | 节点IP | 节点类型 |
Node01 | 10.55.15.89 | NameNode |
Node02 | 10.55.15.65 | DataNode |
Node03 | 10.55.15.91 | DataNade |
2.2 JDK安装及创建 SSH 无密码访问通讯连接
1. 首先 为每台机安装 JDK
使用 root 用户,执行rpm -ivh jdk-7u45-linux-i586.rpm
")
用安装结束后,使用 java –version 检查是否安装好
")
2. SSH创建无密码访问:
a. 使用命令 ssh-keygen -t rsa 分别为三台节点机创建密钥:
此处,以其中一个节点为图例
")
中间过程一路回车就可以,无需填写任何东西
然后,打开隐藏目录 .shh 查看密钥是否生成
")
b. 将共有密钥拷贝一份,重命名为authorized_keys
![]()
c. 将另外两台节点机的共有秒内容也拷贝到 authorized_keys 的内容中
")
d. 将文件 authorized_keys 拷贝到另外两台节点机 .shh 目录下
")
e. 配置 hosts 域名解析
")
f. 测试三台节点机的无密码访问联通性及自访问联通性
")
更多详情见请继续阅读下一页的精彩内容:http://www.linuxidc.com/Linux/2014-06/103504p2.htm
2.3 Hadoop 解压安装及修改配置文件
将 tar 包解压,tar –xzvf hadoop-1.2.1.tar.gz
")
1. 修改core-site.xml
a. 配置 Namenode 主机及端口号
b. 配置制定临时文件夹路径,tmp文件夹要自行创建。
添加内容:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/criss/hadoop/hadoop-1.2.1/tmp</value>
</property>
</configuration>
")
2. 修改 hadoop-env.sh 文件
修改 JDK 的路径
")
3. 修改hdfs-site.xml
节点机数量为 2,value 为2
添加如下内容:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
")
4. 修改mapred-site.xml
配置 job tracter 监听端口监听端口
<property>
<name>mapred.job.tracker</name>
<value>node01:9001</value>
</property>
")
5. 修改 master 和 slaves
修改 master 文件
添加 namenode 主机名
修改slaves
添加 datanode 主机名
")
6. 配置好的 Hadoop 文件夹整体拷贝到各个节点。
![]()
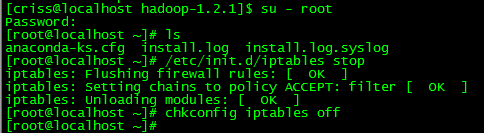
2.4 闭防火墙
关闭每台机的防火墙:
/etc/init.d/iptables stop 关闭防火墙。
chkconfig iptables off 关闭开机启动。
一.环境准备
1. VMware workstation 9
2. Red Hat linux 6.4版本 32bit
3. JDK版本 jdk-7u45-linux-i586
4. Hadoop jar包 1.2.1 版本 32 位
5. 远程登录及 ftp 工具 ( 自选)
备注:
hadoop安装包下载下载地址:hadoop.apache.org
目前最新版本已经更新到 2.2.0 发布版本
二.部署安装步骤
整体分为:
(1)系统安装
(2)JDK安装及创建 SSH 无密码访问通讯连接
(3)Hadoop解压安装配置
(4)配置网络域名解析及关闭放火墙
2.1 安装系统。
安装好虚拟机后,安装 linux 系统,注意网络连接方式选择桥接 ,其他配置根据个人机器情况自行配置。完全分布式共需要准备3 个虚拟机。
————————————– 分割线 ————————————–
Ubuntu 13.04 上搭建 Hadoop 环境 http://www.linuxidc.com/Linux/2013-06/86106.htm
Ubuntu 12.10 +Hadoop 1.2.1 版本集群配置 http://www.linuxidc.com/Linux/2013-09/90600.htm
Ubuntu 上搭建 Hadoop 环境(单机模式 + 伪分布模式)http://www.linuxidc.com/Linux/2013-01/77681.htm
Ubuntu 下 Hadoop 环境的配置 http://www.linuxidc.com/Linux/2012-11/74539.htm
单机版搭建 Hadoop 环境图文教程详解 http://www.linuxidc.com/Linux/2012-02/53927.htm
————————————– 分割线 ————————————–
我设置的实验虚拟机内存为 512M 硬盘为10G:
节点 | 节点IP | 节点类型 |
Node01 | 10.55.15.89 | NameNode |
Node02 | 10.55.15.65 | DataNode |
Node03 | 10.55.15.91 | DataNade |
2.2 JDK安装及创建 SSH 无密码访问通讯连接
1. 首先 为每台机安装 JDK
使用 root 用户,执行rpm -ivh jdk-7u45-linux-i586.rpm
用安装结束后,使用 java –version 检查是否安装好
2. SSH创建无密码访问:
a. 使用命令 ssh-keygen -t rsa 分别为三台节点机创建密钥:
此处,以其中一个节点为图例
中间过程一路回车就可以,无需填写任何东西
然后,打开隐藏目录 .shh 查看密钥是否生成
b. 将共有密钥拷贝一份,重命名为authorized_keys
![]()
c. 将另外两台节点机的共有秒内容也拷贝到 authorized_keys 的内容中
d. 将文件 authorized_keys 拷贝到另外两台节点机 .shh 目录下
e. 配置 hosts 域名解析
f. 测试三台节点机的无密码访问联通性及自访问联通性
更多详情见请继续阅读下一页的精彩内容:http://www.linuxidc.com/Linux/2014-06/103504p2.htm
三.测试启动Hadoop
执行命令可以在任意机器进行操作。
1. 初始化Namenode
Hadoop namenode –format
")
2. 初始化成功后启动
./start-all.sh 启动
")
验证 Namenode 主机进程是否启动成功:
")
验证 Datanode 节点机进程是否启动成功:
")
到此安装部署过程结束!
更多 Hadoop 相关信息见Hadoop 专题页面 http://www.linuxidc.com/topicnews.aspx?tid=13














