")

共计 10602 个字符,预计需要花费 27 分钟才能阅读完成。
高可用基础知识讲解
一、高可用集群的定义
高可用集群,英文原文为 High Availability Cluster,简称 HACluster,简单的说,集群(cluster)就是一组计算机,它们作为一个整体向用户提供一组网络资源。这些单个的计算机系统 就是集群的节点(node)。
高可用集群的出现是为了使集群的整体服务尽可能可用,从而减少由计算机硬件和软件易错性所带来的损失。如果某个节点失效,它的备援节点将在几秒钟的时间内接管它的职责。因此,对于用户而言,集群永远不会停机。高可用集群软件的主要作用就是实现故障检查和业务切换的自动化,当一台服务器出现故障时,可由另一台服务器承担服务任务,从而在不需要人工干预的 情况下,自动保证系统能持续对外提供服务。双机热备只是高可用集群的一种,高可用集群系统更可以支持两个以上的节点,提供比双机热备更多、更高级的功能,更能满足用户不断出现的需求变化。
二、高可用集群的衡量标准
HA(High Available), 高可用性群集是通过系统的可靠性 (reliability) 和可维护性 (maintainability) 来度量的。工程上,通常用平均无故障时间 (MTTF) 来度量系统的可靠性, 用平均维修时间(MTTR)来度量系统的可维护性。于是可用性被定义为:HA=MTTF/(MTTF+MTTR)*100%
————————————– 分割线 ————————————–
相关阅读:
基于 Heartbeat V1 实现 Web 服务双机热备 http://www.linuxidc.com/Linux/2014-04/100635.htm
Heartbeat 实现 Web 服务的高可用群集 http://www.linuxidc.com/Linux/2014-04/99503.htm
Heartbeat+LVS+Ldirectord 高可用负载均衡解决方案 http://www.linuxidc.com/Linux/2014-04/99502.htm
DRBD+Heartbeat+NFS 高可用性配置笔记 http://www.linuxidc.com/Linux/2014-04/99501.htm
Heartbeat 基于 CRM 使用 NFS 对 MySQL 高可用 http://www.linuxidc.com/Linux/2014-03/98674.htm
Heartbeat 高可用 httpd 基于 Resources 简单配置 http://www.linuxidc.com/Linux/2014-03/98672.htm
————————————– 分割线 ————————————–
具体 HA 衡量标准:
99% 一年宕机时间不超过 4 天
99.9% 一年宕机时间不超过 10 小时
99.99% 一年宕机时间不超过 1 小时
99.999% 一年宕机时间不超过 6 分钟

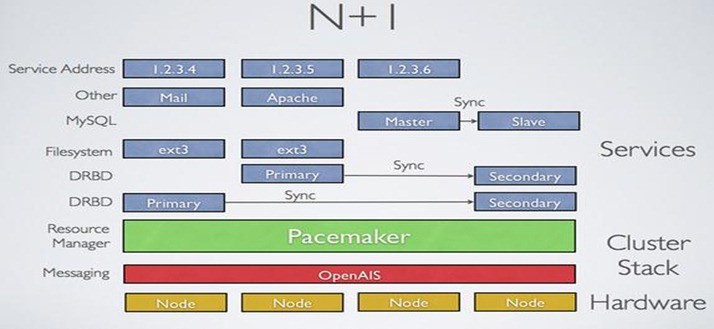
上图是 HA 的工作分层原理图
第一层 messagin layer:心跳信息传递层,能够获知底层服务器资源的在线的情况,并汇报给上一层
第二层 cluster resource manager:集群资源管理层,简称 crm 层,起到承上启下的作用,(其实 local resource manager 做模块
第三层 resource agents:资源代理层:定义资源的
1.ccm 组件(Cluster Consensus Menbership Service):作用,承上启下,监听底层接受的心跳信息,当监听不到心跳信息的时候就重新计算整个集群的票数和收敛状态信息,并将结果转递给上层,让上层做出决定采取怎样的措施,ccm 还能够生成一个各节点状态的拓扑结构概览图,以本节点做为视角,保证该节点在特殊情况下能够采取对应的动作。
2.crmd 组件(Cluster Resource Manager,集群资源管理器,也就是 pacemaker):实现资源的分配,资源分配的每个动作都要通过 crm 来实现,是核心组建,每个节点上的 crm 都维护一个 cib 用来定义资源特定的属性,哪些资源定义在同一个节点上。
3.cib 组件(集群信息基库,Cluster Infonation Base):是 XML 格式的配置文件,在内存中的一个 XML 格式的集群资源的配置文件,主要保存在文件中,工作的时候常驻在内存中并且需要通知给其它节点,只有 DC 上的 cib 才能进行修改,其他节点上的 cib 都是拷贝 DC 上。配置 cib 文件的方法有,基于命令行配置和基于前台的图形界面配置。
4.lrmd 组件(Local Resource Manager,本地资源管理器):用来获取本地某个资源的状态,并且实现本地资源的管理,如当检测到对方没有心跳信息时,来启动本地的服务进程等。
5.pengine 组件:
PE(Policy Engine):策略引擎,来定义资源转移的一整套转移方式,但只是做策略者,并不亲自来参加资源转移的过程,而是让 TE 来执行自己的策略。
TE(Transition Engine):就是来执行 PE 做出的策略的并且只有 DC 上才运行 PE 和 TE。
6.stonithd 组件
STONITH(Shoot The Other Node in the Head,”爆头“),这种方式直接操作电源开关,当一个节点发生故障时,另 一个节点如果能侦测到,就会通过网络发出命令,控制故障节点的电源开关,通过暂时断电,而又上电的方式使故障节点被重启动,这种方式需要硬件支持。
STONITH 应用案例(主从服务器),主服务器在某一端时间由于服务繁忙,没时间响应心跳信息,如果这个时候备用服务器一下子把服务资源抢过去,但是这个时候主服务器还没有宕掉,这样就会导致资源抢占,就这样用户在主从服务器上都能访问,如果仅仅是读操作还没事,要是有写的操作,那就会导致文件系统崩溃,这样一切都玩了,所以在资源抢占的时候,可以采用一定的隔离方法来实现,就是备用服务器抢占资源的时候,直接把主服务器给 STONITH,就是我们常说的”爆头”。

三、高可用集群软件
Messaging and Membership Layer(信息与关系层):
heartbeat (v1,v2,v3),heartbeat v3 分拆 heartbeat pacemaker cluster-glue
corosync
cman
keepalived
ultramokey
Cluster Resource Manager Layer(资源管理层,简称:CRM):
haresource,crm (heartbeat v1/v2)
pacemaker (heartbeat v3/corosync)
rgmanager (cman)
常用组合:
heartbeat v2+haresource(或 crm) (说明:一般常用于 CentOS 5.X)
heartbeat v3+pacemaker (说明:一般常用于 CentOS 6.X)
corosync+pacemaker (说明:现在最常用的组合)
cman + rgmanager (说明:红帽集群套件中的组件,还包括 gfs2,clvm)
keepalived+lvs (说明:常用于 lvs 的高可用)
总结:我们经常在技术博客中看到,heartbeat+pacemaker 实现 mysql 高可用,或 corosync+pacemaker 实现 mysql 高可用等,有的博友会问了,我们到底用什么好呢?经过上面的说明大家应该有所了解!
更多详情见请继续阅读下一页的精彩内容:http://www.linuxidc.com/Linux/2014-09/107264p2.htm
四、共享存储
说到集群,我们不得不说到,共享存储,因为不管理是 Web 高可用也,Mysql 高可用也好,他们的数据都是共享的就一份,所有必须放在共享存储中,主节点能访问,从节点也能访问。下面我们就简单说一下共享存储。
1.DAS:(Direct attached storage)直接附加存储
说明:设备直接连接到主机总线上的,距离有限,而且还要重新挂载,之间有数据传输有延时
RAID 阵列
SCSI 阵列
块级别,块级别的设备会导至中的致数据在共享过程不会被对方知道谁在使用,导致文件错乱
实例:共享文件的同一个文件被 node1 在修改第一行,同时另一个节点 node2 也在修改这个文件的第一行,这在 DAS 和 SAN 是允许的,因为对方不知道谁在用这个文件,就会导致这种问题出现,
2.NAS:(network attached storage)网络附加存储
说明:文件级别的共享
NFS
FTP
CIFS
网络附加存储可以通告给对方谁在用这个文件,但是受限于网络带宽,会导致性能不足,不能为大的专业级公司提供服务
3.SAN:(storage area network)存储区域网络
说明:块级别的,模拟的 scsi 协议
FC 光网络(交换机的光接口超贵,一个差不多 2 万,如果使用这个,代价太高)
IPSAN(iscsi)存取快,块级别,廉价
五、集群文件系统与集群 LVM(集群逻辑卷管理 cLVM)
集群文件系统:gfs2、ocfs2
集群 LVM:cLVM
注:一般用于高可用双主模型中(如下图)
六、高可用集群的工作原理
说明:这里主要以主 / 从节点的高可用来说明工作原理。
主服务器和从服务器建立双机热备,基本上都是共享一个存储,以 mysql 为例。通常情况下,数据库文件挂载在主数据库服务器上,用户连接到主服务器上进行数据库操作。当主服务器出现故障时,从服务器就会自动挂载数据库文件,并接替主服务器的工作。用户在未通知的情况下,通过从数据库连接到数据库文件进行操作。等主服务器的故障修复之后,又可以重新提供服务;
那么,从服务器是如何知道主服务器挂掉了呢,这就要使用一定的检测机制,如心跳检测,也就是说每一个节点都会定期向其他节点通知自己的心跳信息,尤其是主服务器,如果从服务器在几个心跳周期内(可自行设置心跳周期)还没有检测到的话,就认为主服务器宕掉了,而这期间在通告心跳信息当然不能使用 tcp 传输的,如果使用 tcp 检测,还要经过三次握手,等手握完了,不定经过几个心跳周期了,所以在检测心跳信息的时候采用的是 udp 的端口 694 来进行传递信息的,如果主服务器在某一端时间由于服务繁忙,没时间响应心跳信息,这个时候从服务器要是把主服务资源抢过去(共享数据文件),但是这个时候主服务器还没有宕掉,这样就会导致资源抢占,就这样用户在主从上都能访问,如果仅仅是读操作还没事,要是有写的操作,那就会导致文件系统崩溃,这样一切都玩了,所以在资源抢占的时候,可以采用一定的隔离方法来实现,就是从服务器抢占资源的时候,直接把主服务器给“STONITH”,就是我们常说的“爆头”;
那么,我们又用什么方式来检测心跳信息呢?就是通过心跳线来检测。运行在从服务器上的 Heartbeat 可以通过以太网连接检测主服务器的运行状态,一旦其无法检测到主服务器的“心跳”则自动接管主服务器的资源。通常情况下,主、从服务器间的心跳连接是一个独立的物理连接,这个连接可以是串行线缆、一个由“交叉线”实现的以太网连接。Heartbeat 甚至可同时通过多个物理连接检测主服务器的工作状态,而其只要能通过其中一个连接收到主服务器处于活动状态的信息,就会认为主服务器处于正常状态。从实践经验的角度来说,建议为 Heartbeat 配置多条独立的物理连,以避免 Heartbeat 通信线路本身存在单点故障。
上面的原理中我们提到了“隔离方法”,下面我们来说一说,隔离方法有两种,一种是节点隔离,另一种是资源隔离。节点隔离就是我们常说的 STONITH(Shoot The Other Node In the Head,俗称“爆头”),意思就是直接切断电源;常用的方法是所有节点都接在一个电源交换机上,如果有故障,就直接导致该节点的电压不稳定,或断电,让有故障的节点重启或关闭。(如下图),而资源隔离,就是 fencing 直接把某种资源截获过来。

高可用基础知识讲解
一、高可用集群的定义
高可用集群,英文原文为 High Availability Cluster,简称 HACluster,简单的说,集群(cluster)就是一组计算机,它们作为一个整体向用户提供一组网络资源。这些单个的计算机系统 就是集群的节点(node)。
高可用集群的出现是为了使集群的整体服务尽可能可用,从而减少由计算机硬件和软件易错性所带来的损失。如果某个节点失效,它的备援节点将在几秒钟的时间内接管它的职责。因此,对于用户而言,集群永远不会停机。高可用集群软件的主要作用就是实现故障检查和业务切换的自动化,当一台服务器出现故障时,可由另一台服务器承担服务任务,从而在不需要人工干预的 情况下,自动保证系统能持续对外提供服务。双机热备只是高可用集群的一种,高可用集群系统更可以支持两个以上的节点,提供比双机热备更多、更高级的功能,更能满足用户不断出现的需求变化。
二、高可用集群的衡量标准
HA(High Available), 高可用性群集是通过系统的可靠性 (reliability) 和可维护性 (maintainability) 来度量的。工程上,通常用平均无故障时间 (MTTF) 来度量系统的可靠性, 用平均维修时间(MTTR)来度量系统的可维护性。于是可用性被定义为:HA=MTTF/(MTTF+MTTR)*100%
————————————– 分割线 ————————————–
相关阅读:
基于 Heartbeat V1 实现 Web 服务双机热备 http://www.linuxidc.com/Linux/2014-04/100635.htm
Heartbeat 实现 Web 服务的高可用群集 http://www.linuxidc.com/Linux/2014-04/99503.htm
Heartbeat+LVS+Ldirectord 高可用负载均衡解决方案 http://www.linuxidc.com/Linux/2014-04/99502.htm
DRBD+Heartbeat+NFS 高可用性配置笔记 http://www.linuxidc.com/Linux/2014-04/99501.htm
Heartbeat 基于 CRM 使用 NFS 对 MySQL 高可用 http://www.linuxidc.com/Linux/2014-03/98674.htm
Heartbeat 高可用 httpd 基于 Resources 简单配置 http://www.linuxidc.com/Linux/2014-03/98672.htm
————————————– 分割线 ————————————–
具体 HA 衡量标准:
99% 一年宕机时间不超过 4 天
99.9% 一年宕机时间不超过 10 小时
99.99% 一年宕机时间不超过 1 小时
99.999% 一年宕机时间不超过 6 分钟
上图是 HA 的工作分层原理图
第一层 messagin layer:心跳信息传递层,能够获知底层服务器资源的在线的情况,并汇报给上一层
第二层 cluster resource manager:集群资源管理层,简称 crm 层,起到承上启下的作用,(其实 local resource manager 做模块
第三层 resource agents:资源代理层:定义资源的
1.ccm 组件(Cluster Consensus Menbership Service):作用,承上启下,监听底层接受的心跳信息,当监听不到心跳信息的时候就重新计算整个集群的票数和收敛状态信息,并将结果转递给上层,让上层做出决定采取怎样的措施,ccm 还能够生成一个各节点状态的拓扑结构概览图,以本节点做为视角,保证该节点在特殊情况下能够采取对应的动作。
2.crmd 组件(Cluster Resource Manager,集群资源管理器,也就是 pacemaker):实现资源的分配,资源分配的每个动作都要通过 crm 来实现,是核心组建,每个节点上的 crm 都维护一个 cib 用来定义资源特定的属性,哪些资源定义在同一个节点上。
3.cib 组件(集群信息基库,Cluster Infonation Base):是 XML 格式的配置文件,在内存中的一个 XML 格式的集群资源的配置文件,主要保存在文件中,工作的时候常驻在内存中并且需要通知给其它节点,只有 DC 上的 cib 才能进行修改,其他节点上的 cib 都是拷贝 DC 上。配置 cib 文件的方法有,基于命令行配置和基于前台的图形界面配置。
4.lrmd 组件(Local Resource Manager,本地资源管理器):用来获取本地某个资源的状态,并且实现本地资源的管理,如当检测到对方没有心跳信息时,来启动本地的服务进程等。
5.pengine 组件:
PE(Policy Engine):策略引擎,来定义资源转移的一整套转移方式,但只是做策略者,并不亲自来参加资源转移的过程,而是让 TE 来执行自己的策略。
TE(Transition Engine):就是来执行 PE 做出的策略的并且只有 DC 上才运行 PE 和 TE。
6.stonithd 组件
STONITH(Shoot The Other Node in the Head,”爆头“),这种方式直接操作电源开关,当一个节点发生故障时,另 一个节点如果能侦测到,就会通过网络发出命令,控制故障节点的电源开关,通过暂时断电,而又上电的方式使故障节点被重启动,这种方式需要硬件支持。
STONITH 应用案例(主从服务器),主服务器在某一端时间由于服务繁忙,没时间响应心跳信息,如果这个时候备用服务器一下子把服务资源抢过去,但是这个时候主服务器还没有宕掉,这样就会导致资源抢占,就这样用户在主从服务器上都能访问,如果仅仅是读操作还没事,要是有写的操作,那就会导致文件系统崩溃,这样一切都玩了,所以在资源抢占的时候,可以采用一定的隔离方法来实现,就是备用服务器抢占资源的时候,直接把主服务器给 STONITH,就是我们常说的”爆头”。
三、高可用集群软件
Messaging and Membership Layer(信息与关系层):
heartbeat (v1,v2,v3),heartbeat v3 分拆 heartbeat pacemaker cluster-glue
corosync
cman
keepalived
ultramokey
Cluster Resource Manager Layer(资源管理层,简称:CRM):
haresource,crm (heartbeat v1/v2)
pacemaker (heartbeat v3/corosync)
rgmanager (cman)
常用组合:
heartbeat v2+haresource(或 crm) (说明:一般常用于 CentOS 5.X)
heartbeat v3+pacemaker (说明:一般常用于 CentOS 6.X)
corosync+pacemaker (说明:现在最常用的组合)
cman + rgmanager (说明:红帽集群套件中的组件,还包括 gfs2,clvm)
keepalived+lvs (说明:常用于 lvs 的高可用)
总结:我们经常在技术博客中看到,heartbeat+pacemaker 实现 mysql 高可用,或 corosync+pacemaker 实现 mysql 高可用等,有的博友会问了,我们到底用什么好呢?经过上面的说明大家应该有所了解!
更多详情见请继续阅读下一页的精彩内容:http://www.linuxidc.com/Linux/2014-09/107264p2.htm
七、实验
1、首先先两台时间同步
ntpdate 172.16.0.1
保证两台机的时间同步
data -s mm/dd/yy hh/mm/ss
ssh node2.www.org.com “date -s ‘20140914 23:12:30′”;date -s ‘20140914 23:12:30’
前提是做好下面两步才可以使用上面的命令
修改 hostname
vim /etc/hosts
192.168.1.11 node1.www.linuxidc.com node1
192.168.1.12 node2.www.linuxidc.com node2
2、两边都修改,我们可以 ping 一下 node1 测试一下是不是本机 ip 地址
3、基于密钥认证两台机能相互不输入密码登录
ssh-keygen -t rsa
ssh-copy-id -i /root/.ssh/id_rsa.pub root@node2.www.linuxidc.com 可能会出错
我们可以用另外一条命令来复制
ssh-copy-id -i /root/.ssh/id_rsa.pub root@node2 的 ip 地址就不会出错啦
两边都生成,发给对方,这里的话我们可以测试一下是否基于密钥认证成功
ssh node1.linuxidc.com ‘date’;date
4、软件安装
yum 安装四个包有依赖问题,所以只能先解决依赖
yum install perl-TimeDate PyXML libnet net-snmp-libs
这里的话安装 libnet 包没有,不知道咋办,以至于后面的包都无法安装
所于一定要搭建到 yum 源 libnet 在 extra 中
yum install heartbeat-2.1.4-12.el6.x86_64.rpm heartbeat-pils-2.1.4-12.el6.x86_64.rpm heartbeat-stonith-2.1.4-12.el6.x86_64.rpm
cd ~
scp -r heartbeat2/ node2:/root
node2
一样安装软件
yum install perl-TimeDate PyXML libnet net-snmp-libs
yum install heartbeat-2.1.4-12.el6.x86_64.rpm heartbeat-pils-2.1.4-12.el6.x86_64.rpm heartbeat-stonith-2.1.4-12.el6.x86_64.rpm
5、主要配置讲解
配置组播地址 224.0.1.0–238.255.255.255
grep 694 /etc/services
ha.cf 主配置文件
authkeys 认证密钥,其权限必须为组和它无权访问
haresources 用于资源的文件
cd /etc/ha.d
ls
cp /usr/share/doc/heartbeat-2.1.4/{ha.cf,haresources,authkeys} ./
chmod 600 authkeys
cd /etc/ha.cf
6、具体配置
vim ha.cf
启用
logfile /var/log/ha-log 日志
ompression_threshold 2 压缩
mcast eth0 225.100.90.101 694 1 0 广播地址
node node1.www.linuxidc.com
node node2.www.linuxidc.com 配置节点
ping 172.16.0.1 一般为网关 ping 网关
vim authkeys 认证密钥
auth 2
2 sha1 xxxxx 随机码 openssl rand -hex 8
vim haresources
在 virtual
定义资源
主资源 vip(流动 ip)/ 子网 / 网卡别名 / 广播地址 第二个资源 同进同退
node1.linuxidc.com 172.16.100.23/16/eth0/172.16.255.255 httpd
确保有 httpd 资源
定义资源 ip 脚本
ls /etc/ha.d/resource.d
IPaddr 和 IPaddr2
资源 httpd 的脚本
就是 /etc/rc.d/init.d/httpd
scp -p ha.cf haresources authkeys node2:/etc/ha.d
节点二配置把节点一的脚本发过去给他就可以啦
vim /var/www/html/index.html 提供网页
测试一下 curl http://xxxxx
关闭服务 service httpd stop
开机不要启动
chkconfig httpd off
节点 2 一样配置定义 httpd 资源
实验结果测试
主节点
service heartbeat start
ss -unl 694
ssh node2.linuxidc.com ‘service heartbeat start’
tail -f /var/log/ha-log
节点 2 上看 ss -unl 694
ifconfig 看流动 ip 配置上去没有
service heartbeat stop
网页测试是否成功
6、扩展配置
共享 mysql 存储设备提供给网页,做 web 的高可用
172.16.1.143
vim /etc/exports
/www/html 172.16.0.0/16(no_root_squash,rw)
节点上挂载测试网页是否正常
mount -t nfs 172.16.1.143:/www/html /var/www/html
curl http:// 本机 web 服务
关闭全部节点上的 service heartbeat stop
重新定义资源
vim etc/ha.d/haresources
node1.linuxidc.com 172.16.100.23/16/eth0/172.16.255.255 Filesystem::172.16.100.9:/var/www/html::/var/www/html::nfs httpd
scp haresources node2:/etc/ha.d/
service haretbeat start
ssh node2.linuxidc.com ‘service heartbeat start’
mount
ifconfig
mount
7、测试
离线一个节点
测试网页
重启此节点,再离线另一个节点测试
ss -unl
另外一个命令的使用
cd /usr/lib64/heartbeat
hb_standby
hb_takeover
heartbeat v2 配置















