")

共计 3287 个字符,预计需要花费 9 分钟才能阅读完成。
本站提供 Linux 服务器运维,自动化脚本编写等服务,如有需要请联系博主微信:xiaozme
背景
imgurl.org是 xiaoz 2017 年 12 月开始运营的一个图床网站,以下简称ImgURL,ImgURL 运营期间经历了几次迁移,不过当时数据都还不多,没什么难度。随着时间推移数据量越来越多,至今图片数据已经超过 100 万张,截至2022.03.29 已经达到 1176457 张图片。

目前服务器磁盘 IO 压力比较大(主要来自 MySQL 读写压力和图片处理时的压力(图片裁剪、压缩等)),现阶段 ImgURL 托管在 Psychz,由于 Psychz 机械硬盘 IO 太差,准备从 Psychz 的独服迁移到 Kimsufi 独服,在此做一个记录和分享。
网站结构
ImgURL 主要包括:程序(PHP)+ 数据库(MySQL)+ 外部存储三部分组成,其中外部数据又分 4 个,分别为:
- 本地
- Backblaze B2(云上不用考虑迁移)
- FTP
- 自建的 minio(S3)
备注:本地、FTP、minio 数据全部在 Psychz
其中数据量最大的为 FTP 和 minio 数据,分别为:
- FTP:
188GB(文件数量未统计) - minio 数据:
154GB, 对象数量 67 万

数据库迁移
MySQL 数据虽然达到了百万行,但整体数据库不是很大,基本上就是标准的导入、导出操作。
首先导出 MySQL 数据库:
mysqldump -uxxx -pxxx imgurl>imgurl.sql
整个 SQL 文件导出后才 525M, 然后使用scp 命令拷贝迁移(此处省略)
接着是导入数据库:
mysql -u imgurl -p imgurl<imgurl.sql
数据库迁移这个步骤很快就完成了。
备注:不建议使用 MySQL source 命令导入,因为 source 命令会打印每一行操作,百万的数据逐行打印会把你搞奔溃。
迁移网站数据
迁移网站使用的 rsync 命令:
rsync -aqpogt -e 'ssh -p xxx' root@IP:/xxx /xxx
其中参数含义如下:
- -a, –archive 归档模式,表示以递归方式传输文件,并保持所有文件属性
- -q, –quiet 精简输出模式,也可以叫静默模式。这里很重要,因为如果文件很多的时候不使用静默模式会输出一大堆文件
- -p, –perms 保持文件权限。
- -o, –owner 保持文件属主信息。
- -g, –group 保持文件属组信息。
- -t, –times 保持文件时间信息。
-e 'ssh -p xxx'是指定 SSH 端口,因为我使用了非标准 SSH 端口(22)
由于网站程序这部分也不是很大,没有花太长时间。
FTP 数据迁移
由于 FTP 数据达到了 188G,算不上很大,但是小文件特别多,这次依然使用rsync 命令迁移 FTP 数据,不过在迁移之前,我们最好使用 screen 命令,让任务保持在后台运行,避免时间过长,导致窗口任务中断。
| # 新建一个 screen 会话 | |
| screen -S xxx | |
| #使用 rsync 命令迁移 | |
| rsync -aqpogt -e 'ssh -p xxx' root@IP:/xxx /xxx |
这里比较重要的就是需要让任务后台运行,使用 screen 命令或者其它方式都行,毕竟小文件特别多,以免发生中断。整个过程持续了几个小时,具体多长时间忘记了。
最麻烦的部分 minio 数据迁移
xiaoz 使用的 minio 单机版,并没有使用 minio 集群。单机版的数据似乎是直接以源文件存到磁盘的,比较简单的方式就是直接用 rsync 命令同步源文件,但是不清楚这样是否会存在不可知的风险。因此采用了另一个相对保险的方式,使用 rclone sync 进行同步。
我已经提前在 rclone 上配置好了两边的 minio 信息(步骤省略),名称分别为 psychz_s3 和kimsufi_s3,一开始使用命令迁移一个桶中 2021 年的数据:
rclone sync -P psychz_s3:/imgurl/imgs/2021 kimsufi_s3:/imgurl/imgs/2021
持续了 13 个小时,还出现了非常多的报错,报错内容为:
The Content-Md5 you specified did not match what we received.
错误文件次数达到 55269,意味着有55269 个文件因为 MD5 校验没通过而迁移失败。出现这个报错的原因应该是之前我是用了非标操作直接修改了 minio 的源文件(minio 单机版可直接看到源文件并修改,之前直接对这些图片源文件进行了压缩处理,导致 MD5 发生变更)。由于文件数太多,再加上 Psychz 的 IO 比较渣,导致 rclone 在扫描的时候花了非常多的时间。
接着继续对余下的数据做迁移,这次我学聪明了,对命令进行了如下优化:
rclone sync --s3-upload-cutoff 0 --tpslimit 10 --ignore-checksum --size-only -P psychz_s3:/imgurl/imgs/2022/03 kimsufi_s3:/imgurl/imgs/2022/03
–s3-upload-cutoff 0
对于未作为分段上传上传的小对象(–s3-upload-cutoff 如果使用 rclone 上传,则对象大小如下),rclone 使用 ETag: 标头作为 MD5 校验和。
然而,对于作为分段上传或使用服务器端加密(SSE-AWS 或 SSE-C)上传的对象,ETag 标头不再是数据的 MD5 总和,因此 rclone 添加了一个额外的元数据 X -Amz-Meta-Md5chksum,它是一个 base64 编码的 MD5 哈希(与 所需的格式相同 Content-MD5)。
对于大型对象,计算此哈希可能需要一些时间,因此可以使用 禁用添加此哈希 –s3-disable-checksum。这意味着这些对象没有 MD5 校验和。
请注意,从对象中读取它需要额外的 HEAD 请求,因为元数据不会在对象列表中返回。
看了官方的描述,我还是没太搞懂 --s3-upload-cutoff 这个参数的具体含义到底是啥。
–tpslimit 10
这个参数的作用,官方描述如下:
对于未作为分段上传上传的小对象(–s3-upload-cutoff 如果使用 rclone 上传,则对象大小如下),rclone 使用 ETag: 标头作为 MD5 校验和。
然而,对于作为分段上传或使用服务器端加密(SSE-AWS 或 SSE-C)上传的对象,ETag 标头不再是数据的 MD5 总和,因此 rclone 添加了一个额外的元数据 X -Amz-Meta-Md5chksum,它是一个 base64 编码的 MD5 哈希(与 所需的格式相同 Content-MD5)。
对于大型对象,计算此哈希可能需要一些时间,因此可以使用 禁用添加此哈希 –s3-disable-checksum。这意味着这些对象没有 MD5 校验和。
请注意,从对象中读取它需要额外的 HEAD 请求,因为元数据不会在对象列表中返回。
--ignore-checksum这个参数的含义是忽略哈希校验(MD5),对于大量的小文件来说这个参数很有用,但是可靠性可能会降低--size-only:仅校验文件的大小
通过监控观察了下,rclone 优化前和优化后的命令效果显著,系统负载也是直线下降(应该扫描少了)
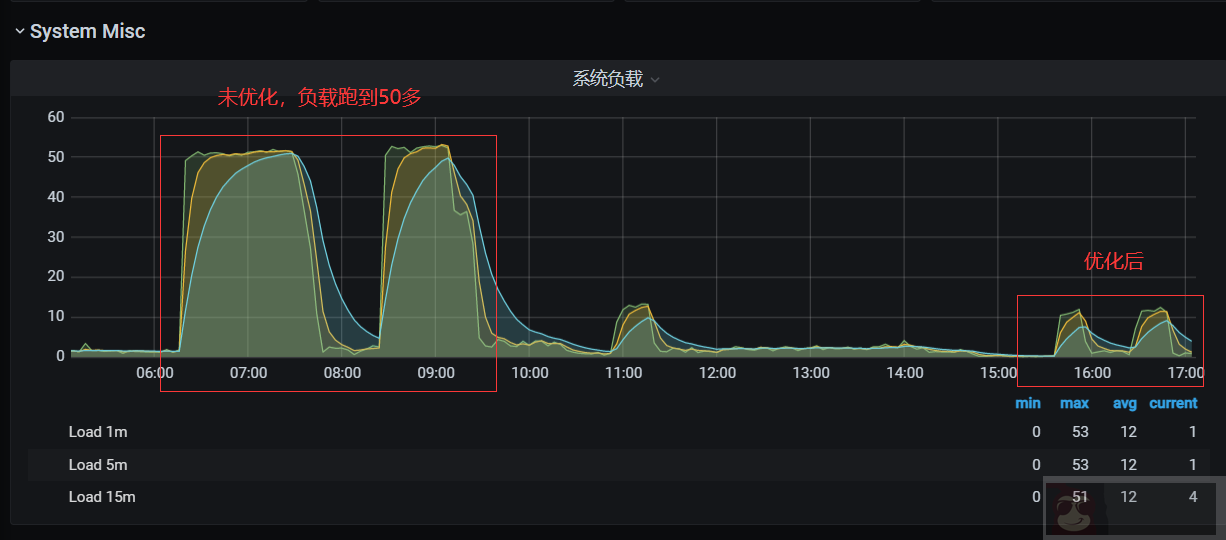
154GB 数据, 对象 67 万,使用 rclone sync 同步 minio 数据花了 30 多个小时。rclone 应该还有其它很多优化参数,有兴趣的小伙伴可以取研究下 rclone 官方文档。
总结
截至 2022.03.30,https://imgurl.org/ 已成功从 Psychz 迁移到了 Kimsufi,整个过程难度不大,但是 rclone sync 同步 minio 数据花费了太多时间。总结如下:
- MySQL 数据导入不推荐
source命令,建议用这种方式:mysql -u imgurl -p imgurl<imgurl.sql - 如果一个任务可能花费的时间特别长,请务必用
screen之类的命令让任务保持后台运行,否则可能因为窗口关闭导致任务中断 rclone sync可通过一系列优化参数提高效率,比如忽略 hash 校验--ignore-checksum- Linux 本地文件迁移,推荐用
rsync,简单又高效















