")

共计 5129 个字符,预计需要花费 13 分钟才能阅读完成。
前段时候做了单机版的 Hadoop on arm 的测试,最近又买了一个新的 arm 板子,就考虑把他们串起来组一个 hadoop 集群。而且由于产品更新换代的问题,硬件上是异构的。
基于 arm 架构单片机的 Hadoop 服务器尝试 http://www.linuxidc.com/Linux/2013-12/94325.htm
namenode 是 cubieboard 一代,采用单核 arm v7 架构,1G 内存,4G 板载 flash ROM
datanode 采用 cubietruck,双核 armv7,2G 内存,8G 板载 Flash ROM,挂了一个 80G 的 2.5 寸磁盘。
两个主板的操作系统均采用 Ubuntu server。
nn 的操作系统装在 SD 卡上,把 nand 分区格式化掉当存储,所谓 nand 就是 flash ROM。
dn 操作系统直接刷在 nand 上,无 SD 卡,挂载一块硬盘当存储。
怎么把 linux 安装到 nand 上这次先不讲,以后单独说。
linaro@namenode:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mmcblk0p2 1.8G 1.1G 600M 66% /
devtmpfs 408M 4.0K 408M 1% /dev
none 408M 128K 408M 1% /tmp
none 82M 164K 82M 1% /run
none 408M 0 408M 0% /var/tmp
none 5.0M 0 5.0M 0% /run/lock
none 408M 0 408M 0% /run/shm
none 100M 0 100M 0% /run/user
/dev/nand 3.8G 75M 3.5G 3% /opt
linaro@datanode-01:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 2.0G 1.3G 648M 67% /
devtmpfs 913M 4.0K 913M 1% /dev
none 4.0K 0 4.0K 0% /sys/fs/cgroup
none 183M 224K 183M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 913M 0 913M 0% /run/shm
none 100M 0 100M 0% /run/user
/dev/nandc 5.1G 139M 4.7G 3% /opt
/dev/sda1 74G 180M 70G 1% /data
linaro@datanode-01:~$
dd 测试一下磁盘性能,nand 读写可以忽略不计,flash ROM 上读写数据的效率可以用惨不忍睹来性能。写数据只有每秒可怜的 5M,读数据每秒 7M,逆天的慢。
如果使用磁盘的性能差不多,就可以拼凑出一个超级屌丝的 Hadoop 集群来用。
写数据性能,没有想象中的快,不过作为一个 N 年前的 80G 2.5 寸,5400 转的 SATA 盘,这个成绩不错了。43.2MB/s
linaro@datanode-01:~$ sudo time dd if=/dev/zero of=/data/1GB bs=4096 count=250000
250000+0 records in
250000+0 records out
1024000000 bytes (1.0 GB) copied, 23.7274 s, 43.2 MB/s
0.28user 11.04system 0:23.73elapsed 47%CPU (0avgtext+0avgdata 776maxresident)k
8inputs+2000000outputs (0major+252minor)pagefaults 0swaps
读数据性能超乎意料的好,惊了。338MB/s。
linaro@datanode-01:~$ sudo time dd if=/data/1GB of=/dev/null bs=4096 count=250000
250000+0 records in
250000+0 records out
1024000000 bytes (1.0 GB) copied, 3.02673 s, 338 MB/s
0.19user 2.80system 0:03.03elapsed 98%CPU (0avgtext+0avgdata 776maxresident)k
0inputs+0outputs (0major+252minor)pagefaults 0swaps
如果是这样,那么当成 Hadoop 服务器肯定是没啥大问题的,本来 hadoop 就是做一次写入多次读取来用的,写入慢一些不怕,只要读取够快就行了。哪怕做 hbase 的在线服务也可以将就。
有图有真相
黑色为 cubieboard 一代,红色板卡为 cubietruck,CT 下面是 80G 硬盘

供电和网络


硬盘连接

前段时候做了单机版的 Hadoop on arm 的测试,最近又买了一个新的 arm 板子,就考虑把他们串起来组一个 hadoop 集群。而且由于产品更新换代的问题,硬件上是异构的。
基于 arm 架构单片机的 Hadoop 服务器尝试 http://www.linuxidc.com/Linux/2013-12/94325.htm
namenode 是 cubieboard 一代,采用单核 arm v7 架构,1G 内存,4G 板载 flash ROM
datanode 采用 cubietruck,双核 armv7,2G 内存,8G 板载 Flash ROM,挂了一个 80G 的 2.5 寸磁盘。
两个主板的操作系统均采用 Ubuntu server。
nn 的操作系统装在 SD 卡上,把 nand 分区格式化掉当存储,所谓 nand 就是 flash ROM。
dn 操作系统直接刷在 nand 上,无 SD 卡,挂载一块硬盘当存储。
怎么把 linux 安装到 nand 上这次先不讲,以后单独说。
linaro@namenode:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mmcblk0p2 1.8G 1.1G 600M 66% /
devtmpfs 408M 4.0K 408M 1% /dev
none 408M 128K 408M 1% /tmp
none 82M 164K 82M 1% /run
none 408M 0 408M 0% /var/tmp
none 5.0M 0 5.0M 0% /run/lock
none 408M 0 408M 0% /run/shm
none 100M 0 100M 0% /run/user
/dev/nand 3.8G 75M 3.5G 3% /opt
linaro@datanode-01:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 2.0G 1.3G 648M 67% /
devtmpfs 913M 4.0K 913M 1% /dev
none 4.0K 0 4.0K 0% /sys/fs/cgroup
none 183M 224K 183M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 913M 0 913M 0% /run/shm
none 100M 0 100M 0% /run/user
/dev/nandc 5.1G 139M 4.7G 3% /opt
/dev/sda1 74G 180M 70G 1% /data
linaro@datanode-01:~$
dd 测试一下磁盘性能,nand 读写可以忽略不计,flash ROM 上读写数据的效率可以用惨不忍睹来性能。写数据只有每秒可怜的 5M,读数据每秒 7M,逆天的慢。
如果使用磁盘的性能差不多,就可以拼凑出一个超级屌丝的 Hadoop 集群来用。
写数据性能,没有想象中的快,不过作为一个 N 年前的 80G 2.5 寸,5400 转的 SATA 盘,这个成绩不错了。43.2MB/s
linaro@datanode-01:~$ sudo time dd if=/dev/zero of=/data/1GB bs=4096 count=250000
250000+0 records in
250000+0 records out
1024000000 bytes (1.0 GB) copied, 23.7274 s, 43.2 MB/s
0.28user 11.04system 0:23.73elapsed 47%CPU (0avgtext+0avgdata 776maxresident)k
8inputs+2000000outputs (0major+252minor)pagefaults 0swaps
读数据性能超乎意料的好,惊了。338MB/s。
linaro@datanode-01:~$ sudo time dd if=/data/1GB of=/dev/null bs=4096 count=250000
250000+0 records in
250000+0 records out
1024000000 bytes (1.0 GB) copied, 3.02673 s, 338 MB/s
0.19user 2.80system 0:03.03elapsed 98%CPU (0avgtext+0avgdata 776maxresident)k
0inputs+0outputs (0major+252minor)pagefaults 0swaps
如果是这样,那么当成 Hadoop 服务器肯定是没啥大问题的,本来 hadoop 就是做一次写入多次读取来用的,写入慢一些不怕,只要读取够快就行了。哪怕做 hbase 的在线服务也可以将就。
有图有真相
黑色为 cubieboard 一代,红色板卡为 cubietruck,CT 下面是 80G 硬盘
CPU info,datanode+tasktracker 双核处理器

Namenode 单核处理器

Namenode 操作系统及 cpu 架构
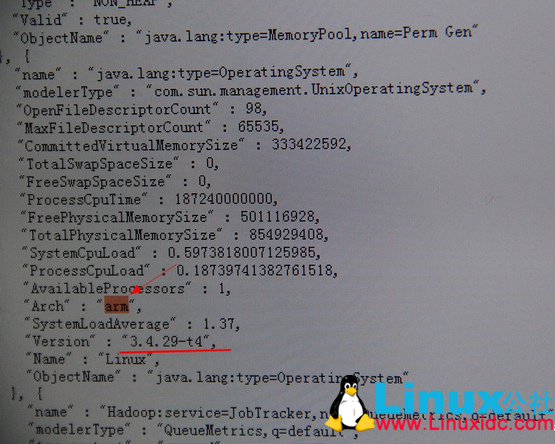
Datanode 操作系统及 CPU 架构

Pi 冒烟测试,至少比我之前单片做 Hadoop 测试要快,如果把 nand 完全不当存储,全释放出来的话,可能还要更快。

namenode 上 nand 当存储使。

datanode 上挂载一个 nand 分区和硬盘共同存储数据。

两台 tasktracker
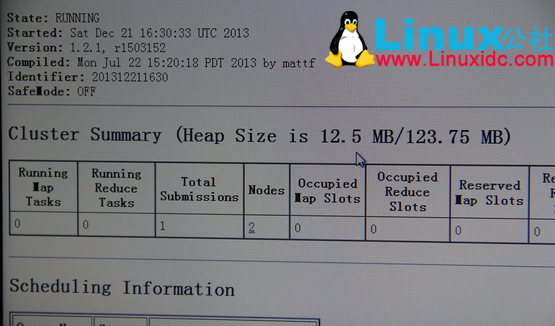
两台 datanode

总容量

arm 因为现在只有 32 位 CPU,所以处理能力很有限,但很高兴的是,这并不影响磁盘性能。我们至少可以组建一个基于 arm 的 Hadoop 存储集群,作为冷数据的存储和备份使用。或者组建一个对线上提供查询服务的 HBASE 集群。这样做的主要好处是成本非常低廉,并且易于维护。
算笔账,一块 arm 板子几百块钱,去掉作为开发板的那些不必要外设,诸如 wifi,火线,HDMI,蓝牙,GPIO 口,SD 卡口的话,还能便宜。1TB 的 2.5 寸 7200 转 sata 盘淘宝售价不到 500。1T 存储的总成本不到 1000,去买块 1T 的 sas 盘也不止这些钱了。
一台 x86 服务器,无硬盘也要 10000 多,假设用 6 块 2T 的 sata 盘,最便宜也要 20000 左右。而采用 arm 方案,12 块 arm 板子加 1T 硬盘再加上电源设备和交换机设备只需要 12000 来块钱,硬件采购成本可以降低 40% 左右。
而更省的是电力成本,一个 arm 板子加硬盘的耗电量大概是 750mA,使用 12V 电源换算成功率大概是 9 瓦 / 时,算算 x86 服务器是多少瓦的?现在 PC 机电源 450 瓦都是起步,Dell R720 的电源功率是 750 瓦。12 个 arm 板子加硬盘的功率才只有 108 瓦。电费节省 600%!!
| 2U 服务器 | arm 开发板 | |
| 数量 | 1 | 12 |
| 磁盘 | 2Tx6=12TB | 1Tx12=12TB |
| 功率 | 750×1=750 瓦 | 9×12=108 瓦 |
至于维护方面,由于 arm 板卡硬盘和服务器一体化,如果有一块硬盘坏了,整体更换即可,无需关闭集群或者做热插拔。
不过还是那句话,arm 现在计算能力不足,无法用做大规模分布式计算,但是这种方式提供冷数据存储备份或小规模 hbase 在线服务是绰绰有余的。但是,这个问题在 2014 年 arm 64 位芯片大规模出货后应该可以得到极大的改善,目前由于 32 位处理器的内存寻址范围只能到 4G,所以还没法做大规模的集群应用,64 位到来后,一切都会好起来。
更多 Hadoop 相关信息见 Hadoop 专题页面 http://www.linuxidc.com/topicnews.aspx?tid=13













