")

共计 19426 个字符,预计需要花费 49 分钟才能阅读完成。
一、ELK 介绍
1.1 elasticsearch
1.1.1 elasticsearch 介绍
ElasticSearch 是一个基于 Lucene 的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口。Elasticsearch 是用 Java 开发的,并作为 Apache 许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
1.1.2 elasticsearch 几个重要术语
NRT
elasticsearch 是一个近似实时的搜索平台,从索引文档到可搜索有些延迟,通常为 1 秒。
集群
集群就是一个或多个节点存储数据,其中一个节点为主节点,这个主节点是可以通过选举产生的,并提供跨节点的联合索引和搜索的功能。集群有一个唯一性标示的名字,默认是 elasticsearch,集群名字很重要,每个节点是基于集群名字加入到其集群中的。因此,确保在不同环境中使用不同的集群名字。一个集群可以只有一个节点。强烈建议在配置 elasticsearch 时,配置成集群模式。
节点
节点就是一台单一的服务器,是集群的一部分,存储数据并参与集群的索引和搜索功能。像集群一样,节点也是通过名字来标识,默认是在节点启动时随机分配的字符名。当然啦,你可以自己定义。该名字也蛮重要的,在集群中用于识别服务器对应的节点。
节点可以通过指定集群名字来加入到集群中。默认情况下,每个节点被设置成加入到 elasticsearch 集群。如果启动了多个节点,假设能自动发现对方,他们将会自动组建一个名为 elasticsearch 的集群。
索引
索引是有几分相似属性的一系列文档的集合。如 nginx 日志索引、syslog 索引等等。索引是由名字标识,名字必须全部小写。这个名字用来进行索引、搜索、更新和删除文档的操作。
索引相当于关系型数据库的库。
类型
在一个索引中,可以定义一个或多个类型。类型是一个逻辑类别还是分区完全取决于你。通常情况下,一个类型被定于成具有一组共同字段的文档。如 chinasoft 所有的数据存入在一个单一的名为 logstash-chinasoft 的索引中,同时,定义了用户数据类型,帖子数据类型和评论类型。
类型相对于关系型数据库的表。
文档
文档是信息的基本单元,可以被索引的。文档是以 JSON 格式表现的。
在类型中,可以根据需求存储多个文档。
虽然一个文档在物理上位于一个索引,实际上一个文档必须在一个索引内被索引和分配一个类型。
文档相对于关系型数据库的列。
分片和副本
在实际情况下,索引存储的数据可能超过单个节点的硬件限制。如一个十亿文档需 1TB 空间可能不适合存储在单个节点的磁盘上,或者从单个节点搜索请求太慢了。为了解决这个问题,elasticsearch 提供将索引分成多个分片的功能。当在创建索引时,可以定义想要分片的数量。每一个分片就是一个全功能的独立的索引,可以位于集群中任何节点上。
分片的两个最主要原因:
a、水平分割扩展,增大存储量
b、分布式并行跨分片操作,提高性能和吞吐量
分布式分片的机制和搜索请求的文档如何汇总完全是有 elasticsearch 控制的,这些对用户而言是透明的。
网络问题等等其它问题可以在任何时候不期而至,为了健壮性,强烈建议要有一个故障切换机制,无论何种故障以防止分片或者节点不可用。
为此,elasticsearch 让我们将索引分片复制一份或多份,称之为分片副本或副本。
副本也有两个最主要原因:
高可用性,以应对分片或者节点故障。出于这个原因,分片副本要在不同的节点上。
提供性能,增大吞吐量,搜索可以并行在所有副本上执行。
总之,每一个索引可以被分成多个分片。索引也可以有 0 个或多个副本。复制后,每个索引都有主分片 (母分片) 和复制分片 (复制于母分片)。分片和副本数量可以在每个索引被创建时定义。索引创建后,可以在任何时候动态的更改副本数量,但是,不能改变分片数。
默认情况下,elasticsearch 为每个索引分片 5 个主分片和 1 个副本,这就意味着集群至少需要 2 个节点。索引将会有 5 个主分片和 5 个副本 (1 个完整副本),每个索引总共有 10 个分片。
每个 elasticsearch 分片是一个 Lucene 索引。一个单个 Lucene 索引有最大的文档数 LUCENE-5843, 文档数限制为 2147483519(MAX_VALUE – 128)。可通过_cat/shards 来监控分片大小。
1.2 logstash
1.2.1 logstash 介绍
LogStash 由 JRuby 语言编写,基于消息(message-based)的简单架构,并运行在 Java 虚拟机(JVM)上。不同于分离的代理端(agent)或主机端(server),LogStash 可配置单一的代理端(agent)与其它开源软件结合,以实现不同的功能。
1.2.2 logStash 的四大组件
Shipper:发送事件(events)至 LogStash;通常,远程代理端(agent)只需要运行这个组件即可;
Broker and Indexer:接收并索引化事件;
Search and Storage:允许对事件进行搜索和存储;
Web Interface:基于 Web 的展示界面
正是由于以上组件在 LogStash 架构中可独立部署,才提供了更好的集群扩展性。
1.2.2 LogStash 主机分类
代理主机(agent host):作为事件的传递者(shipper),将各种日志数据发送至中心主机;只需运行 Logstash 代理(agent)程序;
中心主机(central host):可运行包括中间转发器(Broker)、索引器(Indexer)、搜索和存储器(Search and Storage)、Web 界面端(Web Interface)在内的各个组件,以实现对日志数据的接收、处理和存储。
1.3 kibana
Kibana 也是一个开源和免费的工具,他可以帮助您汇总、分析和搜索重要数据日志并提供友好的 web 界面。他可以为 Logstash 和 ElasticSearch 提供的日志分析的 Web 界面
二、使用 ELK 必要性(解决运维痛点)
开发人员不能登录线上服务器查看详细日志
各个系统都有日志,日至数据分散难以查找
日志数据量大,查询速度慢,或者数据不够实时
三、elk 部署之环境准备
3.1 机器准备
两台虚拟机:
192.168.3.17 node1.chinasoft.com
192.168.3.16 node2.chinasoft.com
关闭防火墙、selinux,时间设置成一样
3.2 系统环境(两台完全一致)
cat /etc/RedHat-release
CentOS release 6.5 (Final)
这里采用 rpm 包安装
rpm -ivh elasticsearch-2.3.3.rpm
rpm -ivh logstash-2.3.2-1.noarch.rpm
安装 kibana
cd /usr/local/src
wget https://download.elastic.co/kibana/kibana/kibana-4.3.1-linux-x64.tar.gz
tar zxf kibana-4.3.1-linux-x64.tar.gz
mv kibana-4.3.1-linux-x64 /usr/local/
ln -s /usr/local/kibana-4.3.1-linux-x64/ /usr/local/kibana
安装 Redis,nginx 和 java
rpm -ivh jdk-8u102-linux-x64.rpm
yum install -y redis nginx
四、管理配置 elasticsearch
4.1 管理 node1.cinasoft.com 的 elasticsearch
修改 elasticsearch 配置文件,并授权
grep -n ‘^[a-Z]’ /etc/elasticsearch/elasticsearch.yml
cluster.name: chinasoft_elk_cluster 判别节点是否是统一集群
node.name: node1.chinasoft.com 节点的 hostname
node.master: true 是否为主节点
path.data: /data/es-data 数据存放路径
path.logs: /var/log/elasticsearch/ 日志路径
bootstrap.mlockall: true 锁住内存,使内存不会再 swap 中使用
network.host: 0.0.0.0 允许访问的 ip
http.port: 9200 端口
mkdir -p /data/es-data
chown elasticsearch.elasticsearch /data/es-data/
启动 elasticsearch
service elasticsearch start
Starting elasticsearch: [OK]
chkconfig elasticsearch on
/etc/init.d/elasticsearch status
elasticsearch (pid 3545) is running…
ss -tunlp|grep 9200
tcp LISTEN 0 50 :::9200 :::* users:((“java”,3545,108))
访问 9200 端口,会把信息显示出来
http://192.168.3.17:9200/
{
“name” : “node1.chinasoft.com”,
“cluster_name” : “chinasoft_elk_cluster”,
“version” : {
“number” : “2.3.3”,
“build_hash” : “218bdf10790eef486ff2c41a3df5cfa32dadcfde”,
“build_timestamp” : “2016-05-17T15:40:04Z”,
“build_snapshot” : false,
“lucene_version” : “5.5.0”
},
“tagline” : “You Know, for Search”
}

4.2 elasticsearch 进行交互
4.2.1 交互的两种方法
Java API:
node client
Transport client
RESTful API
Javascript
.NET
php
Perl
Python
Ruby
4.2.2 使用 RESTful API 进行交互
查看当前索引和分片情况,稍后会有插件展示
curl -i -XGET ‘http://192.168.3.17:9200/_count?pretty’ -d ‘{
“query” {
“match_all”: {}
}
}’
HTTP/1.1 200 OK
Content-Type: application/json; charset=UTF-8
Content-Length: 95
{
“count” : 0, 索引 0 个
“_shards” : {分区 0 个
“total” : 0,
“successful” : 0, 成功 0 个
“failed” : 0 失败 0 个
}
}
使用 head 插件显示索引和分片情况
[root@linux-node1 src]# /usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head
报错:ERROR: failed to download out of all possible locations…, use –verbose to get detailed information
原因:DNS 配置有误,重新配置即可
在插件中添加一个 index-demo/test 的索引,提交请求
http://192.168.3.17:9200/_plugin/head/
{
“_index”: “index-demo”,
“_type”: “test”,
“_id”: “AVgAU8a2aw-Ww-rZC4yF”,
“_version”: 1,
“_shards”: {
“total”: 2,
“successful”: 1,
“failed”: 0
},
“created”: true
}

发送一个 GET(当然可以使用其他类型请求)请求,查询上述索引 id
在基本查询中查看所建索引
4.2 管理 node2.chinasoft.com 的 elasticsearch
将 node1 的配置文件拷贝到 node2 中, 并修改配置文件并授权
配置文件中 cluster.name 的名字一定要一致,当集群内节点启动的时候,默认使用组播(多播),寻找集群中的节点
scp /etc/elasticsearch/elasticsearch.yml 192.168.3.16:/etc/elasticsearch/
node2:
sed -i ‘s#node.name: node1.chinasoft.com#node.name: node2.chinasoft.com#g’ /etc/elasticsearch/elasticsearch.yml
删除这行:
node.master: true
验证:
[root@node2 network-scripts]# egrep -v ‘#|^$’ /etc/elasticsearch/elasticsearch.yml
cluster.name: chinasoft_elk_cluster
node.name: node2.chinasoft.com
path.logs: /var/log/elasticsearch/
bootstrap.mlockall: true
network.host: 0.0.0.0
http.port: 9200
mkdir -p /data/es-data
chown elasticsearch.elasticsearch /data/es-data/
启动 elasticsearch
service elasticsearch start
chkconfig elasticsearch on
在 node2 配置中添加如下内容,使用单播模式(尝试了使用组播,但是不生效)
grep -n “^discovery” /etc/elasticsearch/elasticsearch.yml
discovery.zen.ping.unicast.hosts: [“node1.chinasoft.com”, “node2.chinasoft.com”]
service elasticsearch restart
在浏览器中查看分片信息,一个索引默认被分成了 5 个分片,每份数据被分成了五个分片(可以调节分片数量),下图中外围带绿色框的为主分片,不带框的为副本分片,主分片丢失,副本分片会复制一份成为主分片,起到了高可用的作用,主副分片也可以使用负载均衡加快查询速度,但是如果主副本分片都丢失,则索引就是彻底丢失。
4.3 使用 kopf 插件监控 elasticsearch
/usr/share/elasticsearch/bin/plugin install lmenezes/elasticsearch-kopf
访问:http://192.168.3.17:9200/_plugin/kopf/#!/cluster

点击菜单栏的 nodes 可以看出节点的负载,cpu 适应情况,java 对内存的使用(heap usage),磁盘使用,启动时间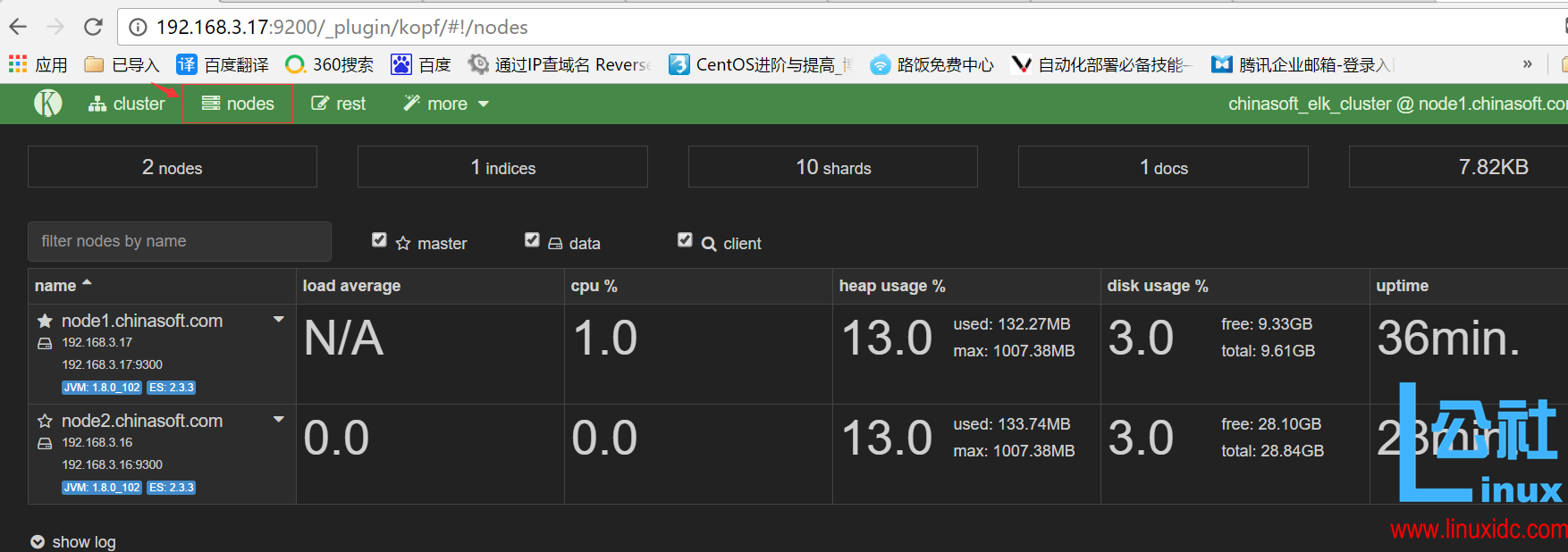
除此之外,kopf 插件还提供了 REST API 等,类似 kopf 插件的还有 bigdesk,但是 bigdesk 目前还不支持 2.1! 安装 bigdesk 的方法如下
/usr/share/elasticsearch/bin/plugin install lukas-vlcek/bigdesk
4.4node 间组播通信和分片


当第一个节点启动,它会组播发现其他节点,发现集群名字一样的时候,就会自动加入集群。随便一个节点都是可以连接的,并不是主节点才可以连接,连接的节点起到的作用只是汇总信息展示
最初可以自定义设置分片的个数,分片一旦设置好,就不可以改变。主分片和副本分片都丢失,数据即丢失,无法恢复,可以将无用索引删除。有些老索引或者不常用的索引需要定期删除,否则会导致 es 资源剩余有限,占用磁盘大,搜索慢等。如果暂时不想删除有些索引,可以在插件中关闭索引,就不会占用内存了。
五、配置 logstash
5.1 循序渐进学习 logstash
启动一个 logstash,-e:在命令行执行;input 输入,stdin 标准输入,是一个插件;output 输出,stdout:标准输出
# /opt/logstash/bin/logstash -e ‘input {stdin{} } output {stdout{} }’ Settings: Debault filter worker: 1
Settings: Default pipeline workers: 2
Pipeline main started
chuck ==> 输入
2016-10-28T03:10:52.276Z node1.chinasoft.com chuck ==> 输出
www.chinasoft.com ==> 输入
2016-10-28T03:11:03.169Z node1.chinasoft.com www.chinasoft.com ==> 输出
使用 rubudebug 显示详细输出,codec 为一种编解码器
# /opt/logstash/bin/logstash -e ‘input {stdin{} } output {stdout{ codec => rubydebug} }’
Settings: Default pipeline workers: 2
Pipeline main started
chunck ==> 输入
{
“message” => “chunck”,
“@version” => “1”,
“@timestamp” => “2016-10-28T03:15:02.824Z”,
“host” => “node1.chinasoft.com”
} ==> 使用 rubydebug 输出
上述每一条输出的内容称为一个事件,多个相同的输出的内容合并到一起称为一个事件(举例:日志中连续相同的日志输出称为一个事件)
使用 logstash 将信息写入到 elasticsearch
# /opt/logstash/bin/logstash -e ‘input {stdin{} } output {elasticsearch { hosts => [“192.168.3.17:9200”] } }’
Settings: Default pipeline workers: 2
Pipeline main started
jack
chunck
www.chinasoft.com

在 elasticsearch 中写一份,同时在本地输出一份,也就是在本地保留一份文本文件,也就不用在 elasticsearch 中再定时备份到远端一份了。此处使用的保留文本文件三大优势:1)文本最简单 2)文本可以二次加工 3)文本的压缩比最高
# /opt/logstash/bin/logstash -e ‘input {stdin{} } output {elasticsearch {hosts => [“192.168.3.17:9200”] } stdout{codec => rubydebug} }’
Settings: Default pipeline workers: 2
Pipeline main started
www.baidu.com
{
“message” => “www.baidu.com”,
“@version” => “1”,
“@timestamp” => “2016-10-28T03:26:18.736Z”,
“host” => “node1.chinasoft.com”
}
www.elastic.co
{
“message” => “www.elastic.co”,
“@version” => “1”,
“@timestamp” => “2016-10-28T03:26:32.609Z”,
“host” => “node1.chinasoft.com”
}
使用 logstash 启动一个配置文件,会在 elasticsearch 中写一份
# vim normal.conf
input {stdin {} }
output {
elasticsearch {hosts => [“192.168.3.17:9200”] }
stdout {codec => rubydebug}
}
# /opt/logstash/bin/logstash -f normal.conf
Settings: Default pipeline workers: 2
Pipeline main started
123
{
“message” => “123”,
“@version” => “1”,
“@timestamp” => “2016-10-28T03:33:35.899Z”,
“host” => “node1.chinasoft.com”
}
chinasoft
{
“message” => “chinasoft”,
“@version” => “1”,
“@timestamp” => “2016-10-28T03:33:44.641Z”,
“host” => “node1.chinasoft.com”
}
5.2 学习编写 conf 格式
输入插件配置,此处以 file 为例,可以设置多个
input {
file {
path => “/var/log/messages”
type => “syslog”
}
file {
path => “/var/log/nginx/access.log”
type => “nginx”
}
}
介绍几种收集文件的方式,可以使用数组方式或者用 * 匹配,也可以写多个 path
path => [“/var/log/messages”,”/var/log/*.log”]
path => [“/data/mysql/mysql.log”]
设置 boolean 值
ssl_enable => true
文件大小单位
my_bytes => “1113” # 1113 bytes
my_bytes => “10MiB” # 10485760 bytes
my_bytes => “100kib” # 102400 bytes
my_bytes => “180 mb” # 180000000 bytes
jason 收集
codec =>“json”
hash 收集
match => {
“field1” => “value1”
“field2” => “value2”
…
}
端口
port => 21
密码
my_password => “password”
5.3 学习编写 input 的 file 插件
5.3.1 input 插件之 input

sincedb_path:记录 logstash 读取位置的路径
start_postion : 包括 beginning 和 end,指定收集的位置,默认是 end,从尾部开始
add_field 加一个域
discover_internal 发现间隔,每隔多久收集一次,默认 15 秒
5.4 学习编写 output 的 file 插件

5.5 通过 input 和 output 插件编写 conf 文件
5.5.1 收集系统日志的 conf
————————————————
# vim nginx.conf
input {
file {
path => “/var/log/nginx/access.log”
type => “nginx”
start_position => “beginning”
}
}
output {
elasticsearch {
hosts => [“192.168.3.17:9200”]
index => “nginx-%{+YYYY.MM.dd}”
}
}
# /opt/logstash/bin/logstash -f nginx.conf
————————————————


5.5.2 收集 elasticsearch 的 error 日志
此处把上个 system 日志和这个 error(java 程序日志)日志,放在一起。使用 if 判断,两种日志分别写到不同索引中. 此处的 type(固定的就是 type,不可更改)不可以和日志格式的任何一个域(可以理解为字段)的名称重复,也就是说日志的域不可以有 type 这个名称。
vim all.conf
input {
file {
path => “/var/log/nginx/access.log”
type => “nginx”
start_position => “beginning”
}
file {
path => “/var/log/elasticsearch/chinasoft_elk_cluster.log”
type => “es-error”
start_position => “beginning”
}
}
output {
if [type] == “nginx” {
elasticsearch {
hosts => [“192.168.3.17:9200”]
index => “nginx-%{+YYYY.MM.dd}”
}
}
if [type] == “es-error” {
elasticsearch {
hosts => [“192.168.3.17:9200”]
index => “es-error-%{+YYYY.MM.dd}”
}
}
}
5.6 把多行整个报错收集到一个事件中
5.6.1 举例说明
以 at.org 开头的内容都属于同一个事件,但是显示在不同行,这样的日志格式看起来很不方便,所以需要把他们合并到一个事件中

5.6.2 引入 codec 的 multiline 插件
官方文档提供
input {
stdin {
codec => multiline {
` pattern => “pattern, a regexp”
negate => “true” or “false”
what => “previous” or “next”`
}
}
}
regrxp:使用正则,什么情况下把多行合并起来
negate: 正向匹配和反向匹配
what: 合并到当前行还是下一行
在标准输入和标准输出中测试以证明多行收集到一个日志成功
vim muliline.conf
input {
stdin {
codec => multiline {
pattern => “^\[“
negate => true
what => “previous”
}
}
}
output {
stdout {
codec => “rubydebug”
}
}
# /opt/logstash/bin/logstash -f muliline.conf
Settings: Default pipeline workers: 2
Pipeline main started
[1
Received an event that has a different character encoding than you configured. {:text=>”\\xE3[1\\n”, :expected_charset=>”UTF-8″, :level=>:warn}
[2
{
“@timestamp” => “2016-10-28T06:19:59.275Z”,
“message” => “\\xE3[1\\n”,
“@version” => “1”,
“host” => “node1.chinasoft.com”
}
{
chinasoft
chinasoft.com
123456
[3
{
“@timestamp” => “2016-10-28T06:21:13.812Z”,
“message” => “[2\n{\nchinasoft\nchinasoft.com\n123456”,
“@version” => “1”,
“tags” => [
[0] “multiline”
],
“host” => “node1.chinasoft.com”
}
继续将上述实验结果放到 all.conf 的 es-error 索引中
vim all.conf
input {
file {
path => “/var/log/nginx/access.log”
type => “nginx”
start_position => “beginning”
}
file {
path => “/var/log/elasticsearch/chuck-clueser.log”
type => “es-error”
start_position => “beginning”
codec => multiline {
pattern => “^\[“
negate => true
what => “previous”
}
}
}
output {
if [type] == “nginx” {
elasticsearch {
hosts => [“192.168.3.17:9200”]
index => “nginx-%{+YYYY.MM.dd}”
}
}
if [type] == “es-error” {
elasticsearch {
hosts => [“192.168.3.17:9200”]
index => “es-error-%{+YYYY.MM.dd}”
}
}
}
六、熟悉 kibana
6.1 编辑 kinaba 配置文件使之生效
# grep ‘^[a-Z]’ /usr/local/kibana/config/kibana.yml
server.port: 5601 # kibana 端口
server.host: “0.0.0.0” 对外服务的主机
elasticsearch.url: “http://192.168.3.17:9200” # 和 elasticsearch 联系
kibana.index: ” .kibana # 在 elasticsearch 中添加.kibana 索引
开启一个 screen,并启动 kibana
yum install -y screen
# screen
# /usr/local/kibana/bin/kibana
使用 crtl +a+ d 退出 screen
使用浏览器打开 192.168.3.17:5601
6.2 验证 error 的 muliline 插件生效
在 kibana 中添加一个 es-error 索引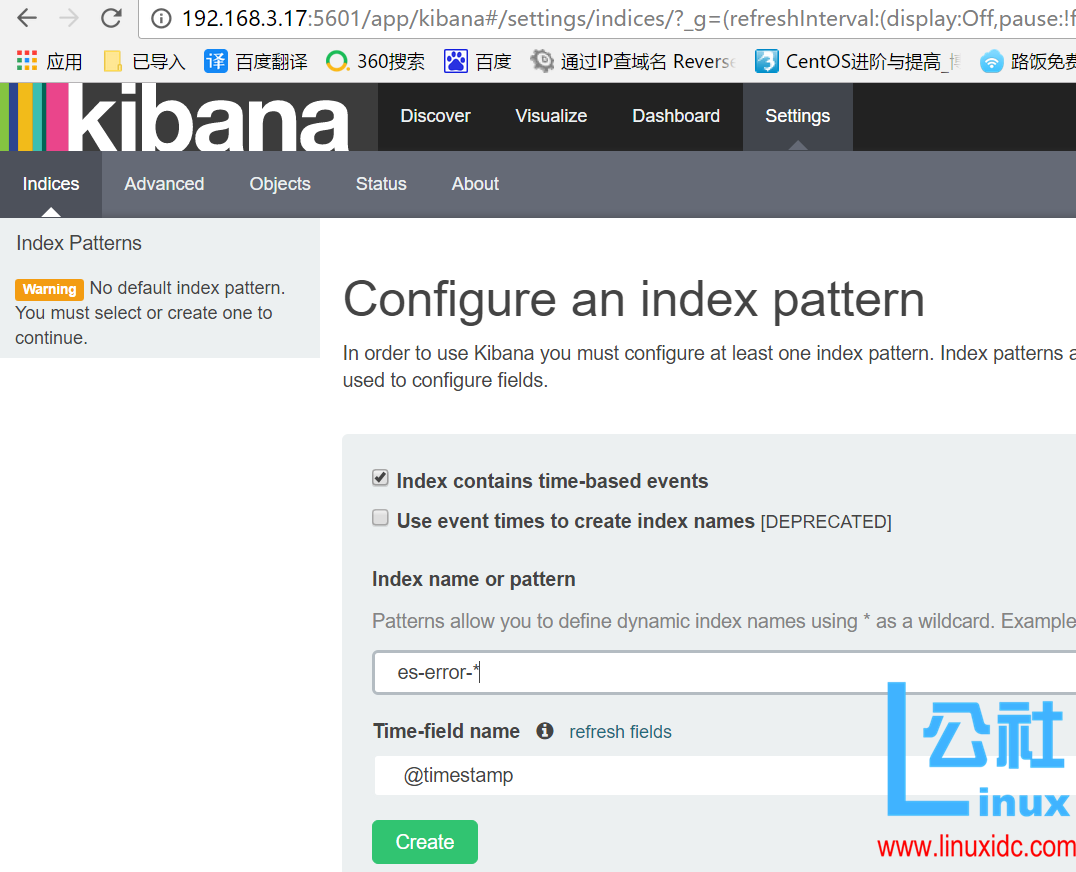
可以看到默认的字段
选择 discover 查看
验证 error 的 muliline 插件生效 (即过滤条件,将多行错误转为一行)
七、logstash 收集 nginx、syslog 和 tcp 日志
7.1 收集 nginx 的访问日志
在这里使用 codec 的 json 插件将日志的域进行分段,使用 key-value 的方式,使日志格式更清晰,易于搜索,还可以降低 cpu 的负载
更改 nginx 的配置文件的日志格式,使用 json
vim /etc/nginx/nginx.conf
log_format json ‘{“@timestamp”: “$time_local”, ‘
‘”@fields”: {‘
‘”remote_addr”: “$remote_addr”, ‘
‘”remote_user”: “$remote_user”, ‘
‘”body_bytes_sent”: “$body_bytes_sent”, ‘
‘”request_time”: “$request_time”, ‘
‘”status”: “$status”, ‘
‘”request”: “$request”, ‘
‘”request_method”: “$request_method”, ‘
‘”http_referrer”: “$http_referer”, ‘
‘”body_bytes_sent”:”$body_bytes_sent”, ‘
‘”http_x_forwarded_for”: “$http_x_forwarded_for”, ‘
‘”http_user_agent”: “$http_user_agent” } }’;
# access_log /var/log/nginx/access_json.log main;
access_log /var/log/nginx/access.log json;
重新启动 nginx
# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
# ss -tunlp|grep nginx
tcp LISTEN 0 128 *:80 *:* users:((“nginx”,13590,6),(“nginx”,13591,6))
日志格式显示如下

使用 logstash 将 nginx 访问日志收集起来,继续写到 all.conf 中
将 nginx-log 加入 kibana 中并显示

7.2 收集系统 syslog 日志
前文中已经使用文件 file 的形式收集了系统日志 /var/log/messages,但是实际生产环境是需要使用 syslog 插件直接收集
修改 syslog 的配置文件,把日志信息发送到 514 端口上
# vim /etc/rsyslog.conf
90 *.* @@192.168.3.17
# service rsyslog restart
将 system-syslog 放到 all.conf 中,启动 all.conf
input {
syslog {
type => “system-syslog”
host => “192.168.3.17”
port => “514”
}
file {
path => “/var/log/nginx/access.log”
type => “nginx”
start_position => “beginning”
}
file {
path => “/var/log/elasticsearch/chuck-clueser.log”
type => “es-error”
start_position => “beginning”
codec => multiline {
pattern => “^\[“
negate => true
what => “previous”
}
}
}
output {
if [type] == “nginx” {
elasticsearch {
hosts => [“192.168.3.17:9200”]
index => “nginx-%{+YYYY.MM.dd}”
}
}
if [type] == “es-error” {
elasticsearch {
hosts => [“192.168.3.17:9200”]
index => “es-error-%{+YYYY.MM.dd}”
}
}
if [type] == “system-syslog” {
elasticsearch {
hosts => [“192.168.3.17:9200”]
index => “system-syslog-%{+YYYY.MM.dd}”
}
}
}
在 elasticsearch 插件中就可见到增加的 system-syslog 索引
7.3 收集 tcp 日志
编写 tcp.conf
# vim tcp.conf
input {
tcp {
host => “192.168.3.17”
port => “6666”
}
}
output {
stdout {
codec => “rubydebug”
}
}
使用 nc 对 6666 端口写入数据
# nc 192.168.3.17 6666 </var/log/yum.log
将信息输入到 tcp 的伪设备中
将信息输入到 tcp 的伪设备中
# echo “chinasoft” >/dev/tcp/192.168.3.17/6666
八、logstash 解耦之消息队列
8.1 图解使用消息队列架构
数据源 Datasource 把数据写到 input 插件中,output 插件使用消息队列把消息写入到消息队列 Message Queue 中,Logstash indexing Instance 启动 logstash 使用 input 插件读取消息队列中的信息,Fliter 插件过滤后在使用 output 写入到 elasticsearch 中。
如果生产环境中不适用正则 grok 匹配,可以写 Python 脚本从消息队列中读取信息,输出到 elasticsearch 中


8.2 上图架构的优点
解耦,松耦合
解除了由于网络原因不能直接连 elasticsearch 的情况
方便架构演变,增加新内容
消息队列可以使用 rabbitmq,zeromq 等,也可以使用 redis,kafka(消息不删除,但是比较重量级)等
九、引入 redis 到架构中
9.1 使用 redis 收集 logstash 的信息
修改 redis 的配置文件并启动 redis
vim /etc/redis.conf
daemonize yes
bind 192.168.3.17
service redis restart
# ss -tunlp|grep 6379
tcp LISTEN 0 128 192.168.3.17:6379 *:* users:((“redis-server”,17337,4))
编写 redis.conf
# vim redis-out.conf
input{
stdin{
}
}
output{
redis{
host => “192.168.3.17”
port => “6379”
db => “6”
data_type => “list” # 数据类型为 list
key => “demo”
}
}
启动配置文件输入信息
# /opt/logstash/bin/logstash -f redis-out.conf
Settings: Default pipeline workers: 2
Pipeline main started
chinasoft
chinasoft.com
使用 redis-cli 连接到 redis 并查看输入的信息
# redis-cli -h 192.168.3.17
redis 192.168.3.17:6379> info
redis_version:2.4.10
redis_git_sha1:00000000
redis_git_dirty:0
arch_bits:64
multiplexing_api:epoll
gcc_version:4.4.6
process_id:17337
uptime_in_seconds:563
uptime_in_days:0
lru_clock:988645
used_cpu_sys:0.13
used_cpu_user:0.11
used_cpu_sys_children:0.00
used_cpu_user_children:0.00
connected_clients:2
connected_slaves:0
client_longest_output_list:0
client_biggest_input_buf:0
blocked_clients:0
used_memory:735488
used_memory_human:718.25K
used_memory_rss:1454080
used_memory_peak:735416
used_memory_peak_human:718.18K
mem_fragmentation_ratio:1.98
mem_allocator:jemalloc-2.2.5
loading:0
aof_enabled:0
changes_since_last_save:2
bgsave_in_progress:0
last_save_time:1477892296
bgrewriteaof_in_progress:0
total_connections_received:2
total_commands_processed:3
expired_keys:0
evicted_keys:0
keyspace_hits:0
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:0
vm_enabled:0
role:master
db6:keys=1,expires=0
redis 192.168.3.17:6379> select 6 #选择 db6
OK
redis 192.168.3.17:6379[6]> keys * #选择 demo 这个 key
1) “demo”
redis 192.168.3.17:6379[6]> LINDEX demo -2 #查看消息
“{\”message\”:\”chinasoft\”,\”@version\”:\”1\”,\”@timestamp\”:\”2016-10-31T05:44:02.823Z\”,\”host\”:\”node1.chinasoft.com\”}”
redis 192.168.3.17:6379[6]> LINDEX demo -1 #查看消息
“{\”message\”:\”chinasoft.com\”,\”@version\”:\”1\”,\”@timestamp\”:\”2016-10-31T05:44:15.855Z\”,\”host\”:\”node1.chinasoft.com\”}”
为了下一步写 input 插件到把消息发送到 elasticsearch 中,多在 redis 中写入写数据
# /opt/logstash/bin/logstash -f redis-out.conf
Settings: Default pipeline workers: 2
Pipeline main started
chinasoft
chinasoft.com
a
b
c
d
….
查看 redis 中名字为 demo 的 key 长度
redis 192.168.3.17:6379[6]> llen demo
(integer) 37
9.3 将 all.conf 的内容改为经由 redis
编写 shipper.conf 作为 redis 收集 logstash 配置文件
# cp all.conf shipper.conf
# vim shipper.conf
————————————-
input {
syslog {
type => “system-syslog”
host => “192.168.3.17”
port => “514”
}
file {
path => “/var/log/nginx/access.log”
type => “nginx”
start_position => “beginning”
}
file {
path => “/var/log/elasticsearch/chuck-clueser.log”
type => “es-error”
start_position => “beginning”
codec => multiline {
pattern => “^\[“
negate => true
what => “previous”
}
}
}
output {
if [type] == “nginx” {
redis{
host => “192.168.3.17”
port => “6379”
db => “6”
data_type => “list”
key => “nginx”
}
}
if [type] == “es-error” {
redis {
host => “192.168.3.17”
port => “6379”
db => “6”
data_type => “list”
key => “es-error”
}
}
if [type] == “system-syslog” {
redis{
host => “192.168.3.17”
port => “6379”
db => “6”
data_type => “list”
key => “system-syslog”
}
}
}
————————————-
# /opt/logstash/bin/logstash -f shipper.conf
Settings: Default pipeline workers: 2
Pipeline main started
在 redis 中查看 keys
192.168.56.11:6379[6]> select 6
OK
192.168.56.11:6379[6]> keys *
1) “demo”
2) “nginx”
在别的机器上用 ab 进行对 3.17 的 nginx 进行压力测试,可以看到 redis 的变化
# ab -c 10 -n 100000 http://192.168.3.17/
redis 192.168.3.17:6379[6]> llen nginx
(integer) 10002
redis 192.168.3.17:6379[6]> llen nginx
(integer) 11989
redis 192.168.3.17:6379[6]> llen nginx
(integer) 12878
redis 192.168.3.17:6379[6]> llen nginx
(integer) 13757
编写 indexer.conf 作为 redis 发送 elasticsearch 配置文件 (配置文件报错:Redis connection problem {:exception=>#<Redis::CommandError: ERR unknown command ‘script’>, :level=>:warn}
) 测试不成功
# cat indexer.conf
input {
redis {
type => “system-syslog”
host => “192.168.3.17”
port => “6379”
db => “6”
data_type => “list”
key => “system-syslog”
}
redis {
type => “nginx”
host => “192.168.3.17”
port => “6379”
db => “6”
data_type => “list”
key => “nginx”
}
redis {
type => “es-error”
host => “192.168.3.17”
port => “6379”
db => “6”
data_type => “list”
key => “nginx”
}
}
output {
if [type] == “system-syslog” {
elasticsearch {
hosts => [“192.168.3.17:9200”]
index => “system-syslog-%{+YYYY.MM.dd}”
}
}
if [type] == “nginx” {
elasticsearch {
hosts => [“192.168.3.17:9200”]
index => “nginx-%{+YYYY.MM.dd}”
}
}
if [type] == “es-error” {
elasticsearch {
hosts => [“192.168.3.17:9200”]
index => “es-error-%{+YYYY.MM.dd}”
}
}
}
启动 indexer.conf
# /opt/logstash/bin/logstash -f indexer.conf
Settings: Default filter workers: 1
由于日志量小,很快就会全部被发送到 elasticsearch,key 也就没了,所以多写写数据到日志中
# for n in `seq 10000` ;do echo $n >>/var/log/nginx/access.log;done
# for n in `seq 10000` ;do echo $n >>/var/log/messages;done
十、生产如何上线 ELK。
10.1 日志分类
系统日志 rsyslog logstash syslog 插件
访问日志 nginx logstash codec json
错误日志 file logstash file+ mulitline
运行日志 file logstash codec json
设备日志 syslog logstash syslog 插件
debug 日志 file logstash json or mulitline
10.2 日志标准化
1)路径固定标准化
2)格式尽量使用 json
10.3 日志收集步骤
系统日志开始 -> 错误日志 -> 运行日志 -> 访问日志
前文学习了 input 和 output 插件,在这里学习 fliter 插件
kibana 中搜索状态码为 200 或者 302 的访问记录:
status 302 or status 200
在客户端安装
本文永久更新链接地址:http://www.linuxidc.com/Linux/2016-11/137641.htm















