")

共计 11036 个字符,预计需要花费 28 分钟才能阅读完成。
简介
Ganglia 可以监控分布式集群中硬件资源的使用情况,例如 CPU,内存,网络等资源。通过 Ganglia 可以监控 Hadoop 集群在运行过程中对集群资源的调度,作为简单地运维参考。
环境搭建流程
1、我们先在主机 master01 上面搭建好 Ganglia 环境
2、在 master01 主机上解压 JDK 和 Hadoop 到安装目录、修改配置文件
3、克隆出两台主机 slave01,slave02 并修改主机名和 IP 主机名映射、做免密码登录
4、启动 Ganglia 和 Hadoop 集群、实现 wordcount 实例
关闭防火墙和 Selinux
关闭防火墙和 Selinux 是因为这两者会对 Ganglia 和 Hadoop 环境搭建造成影响,比如防火墙会导致集群间一些通信问题。
关闭防火墙
临时和永久关闭防火墙
临时:
service iptables stop
永久:
chkconfig iptables off

关闭 Selinux
vi /etc/sysconfig/selinux
修改内容如下:

使配置生效:
setenforce 0
Ganglia 单机环境搭建
Ganglia 简介
Ganglia 是 UC Berkeley 发起的一个开源监视项目,设计用于测量数以千计的节点。每台计算机都运行一个收集和发送度量数据(如处理器速度、内存使用量等)的名为 gmond 的守护进程。它将从操作系统和指定主机中收集。接收所有度量数据的主机可以显示这些数据并且可以将这些数据的精简表单传递到层次结构中。正因为有这种层次结构模式,才使得 Ganglia 可以实现良好的扩展。gmond 带来的系统负载非常少,这使得它成为在集群中各台计算机上运行的一段代码,而不会影响用户性能。
一、Ganglia 组件
Ganglia 监控套件包括三个主要部分:gmond,gmetad,和网页接口,通常被称为 ganglia-web。
Gmond : 是一个守护进程,他运行在每一个需要监测的节点上,收集监测统计,发送和接受在同一个组播或单播通道上的统计信息 如果他是一个发送者 (mute=no) 他会收集基本指标,比如系统负载(load_one),CPU 利用率。他同时也会发送用户通过添加 C /Python 模块来自定义的指标。如果他是一个接收者(deaf=no)他会聚合所有从别的主机上发来的指标,并把它们都保存在内存缓冲区中。
Gmetad: 也是一个守护进程,他定期检查 gmonds,从那里拉取数据,并将他们的指标存储在 RRD 存储引擎中。他可以查询多个集群并聚合指标。他也被用于生成用户界面的 web 前端。
Ganglia-web : 顾名思义,他应该安装在有 gmetad 运行的机器上,以便读取 RRD 文件。集群是主机和度量数据的逻辑分组,比如数据库服务器,网页服务器,生产,测试,QA 等,他们都是完全分开的,你需要为每个集群运行单独的 gmond 实例。
一般来说集群中每个节点需要一个接收的 gmond,每个网站需要一个 gmetad。
二、安装依赖
注:建议使用超级用户安装
yum install –y gcc gcc-c++ libpng freetype zlib libdbi apr* libxml2-devel pkg-config glib pixman pango pango-devel freetye-devel fontconfig cairo cairo-devel libart_lgpl libart_lgpl-devel pcre* rrdtool*


三、安装 expat 依赖
cd /root
wget http://jaist.dl.sourceforge.net/project/expat/expat/2.1.0/expat-2.1.0.tar.gz
tar -xf expat-2.1.0.tar.gz && cd expat-2.1.0 && ./configure –prefix=/usr/local/expat && make && make install && cd ..

四、安装 confuse
wget http://ftp.twaren.net/Unix/NonGNU//confuse/confuse-2.7.tar.gz
tar -xf confuse-2.7.tar.gz && cd confuse-2.7 && ./configure CFLAGS=-fPIC –disable-nls –prefix=/usr/local/confuse && make && make install && cd ..

64bit 机器需要拷贝动态链接库:
mkdir -p /usr/local/confuse/lib64 && cp -a -f /usr/local/confuse/lib/* /usr/local/confuse/lib64/
更多详情见请继续阅读下一页的精彩内容:http://www.linuxidc.com/Linux/2017-03/141652p2.htm
五、安装 ganglia
wget http://jaist.dl.sourceforge.net/project/ganglia/ganglia%20monitoring%20core/3.6.0/ganglia-3.6.0.tar.gz
tar -xf ganglia-3.6.0.tar.gz && cd ganglia-3.6.0 && ./configure –with-gmetad –enable-gexec –with-libconfuse=/usr/local/confuse –with-libexpat=/usr/local/expat –prefix=/usr/local/ganglia –sysconfdir=/etc/ganglia && make && make install && cd ..

六、服务端配置
创建 rrdtool 数据目录,看 $ganglia-3.2.0/web/conf.PHP 里面的 gmetad_root 变量,并根据 apache 的运行用户创建权限,例如 apache 运行于 apache 用户上。
mkdir -p /var/lib/ganglia/rrds && mkdir -p /var/lib/ganglia/dwoo && chown -R root:root /var/lib/ganglia
配置一个数据源,修改 /etc/ganglia/gmetad.conf 文件,同时将运行用户设置为 rrdtool 的目录权限用户,例如 apache 用户
data_source “Hadoop” 192.168.1.108:8649
setuid_username “root”
说明:这里的 ” hadoop ” 表示的是集群的名称,后面的内容是这个集群中所包含的主机信息,也就是要监控的主机 ip。
添加自启动脚本
cp -f ganglia-3.6.0/gmetad/gmetad.init /etc/init.d/gmetad && cp -f /usr/local/ganglia/sbin/gmetad /usr/sbin/gmetad && chkconfig –add gmetad
启动 gmetad 服务
service gmetad start
看见 Starting GANGLIA gmetad: [OK]就代表运行正常了。通过 telnet localhost 8651 验证 gmetad 是否正常。

简介
Ganglia 可以监控分布式集群中硬件资源的使用情况,例如 CPU,内存,网络等资源。通过 Ganglia 可以监控 Hadoop 集群在运行过程中对集群资源的调度,作为简单地运维参考。
环境搭建流程
1、我们先在主机 master01 上面搭建好 Ganglia 环境
2、在 master01 主机上解压 JDK 和 Hadoop 到安装目录、修改配置文件
3、克隆出两台主机 slave01,slave02 并修改主机名和 IP 主机名映射、做免密码登录
4、启动 Ganglia 和 Hadoop 集群、实现 wordcount 实例
关闭防火墙和 Selinux
关闭防火墙和 Selinux 是因为这两者会对 Ganglia 和 Hadoop 环境搭建造成影响,比如防火墙会导致集群间一些通信问题。
关闭防火墙
临时和永久关闭防火墙
临时:
service iptables stop
永久:
chkconfig iptables off
关闭 Selinux
vi /etc/sysconfig/selinux
修改内容如下:
使配置生效:
setenforce 0
Ganglia 单机环境搭建
Ganglia 简介
Ganglia 是 UC Berkeley 发起的一个开源监视项目,设计用于测量数以千计的节点。每台计算机都运行一个收集和发送度量数据(如处理器速度、内存使用量等)的名为 gmond 的守护进程。它将从操作系统和指定主机中收集。接收所有度量数据的主机可以显示这些数据并且可以将这些数据的精简表单传递到层次结构中。正因为有这种层次结构模式,才使得 Ganglia 可以实现良好的扩展。gmond 带来的系统负载非常少,这使得它成为在集群中各台计算机上运行的一段代码,而不会影响用户性能。
一、Ganglia 组件
Ganglia 监控套件包括三个主要部分:gmond,gmetad,和网页接口,通常被称为 ganglia-web。
Gmond : 是一个守护进程,他运行在每一个需要监测的节点上,收集监测统计,发送和接受在同一个组播或单播通道上的统计信息 如果他是一个发送者 (mute=no) 他会收集基本指标,比如系统负载(load_one),CPU 利用率。他同时也会发送用户通过添加 C /Python 模块来自定义的指标。如果他是一个接收者(deaf=no)他会聚合所有从别的主机上发来的指标,并把它们都保存在内存缓冲区中。
Gmetad: 也是一个守护进程,他定期检查 gmonds,从那里拉取数据,并将他们的指标存储在 RRD 存储引擎中。他可以查询多个集群并聚合指标。他也被用于生成用户界面的 web 前端。
Ganglia-web : 顾名思义,他应该安装在有 gmetad 运行的机器上,以便读取 RRD 文件。集群是主机和度量数据的逻辑分组,比如数据库服务器,网页服务器,生产,测试,QA 等,他们都是完全分开的,你需要为每个集群运行单独的 gmond 实例。
一般来说集群中每个节点需要一个接收的 gmond,每个网站需要一个 gmetad。
二、安装依赖
注:建议使用超级用户安装
yum install –y gcc gcc-c++ libpng freetype zlib libdbi apr* libxml2-devel pkg-config glib pixman pango pango-devel freetye-devel fontconfig cairo cairo-devel libart_lgpl libart_lgpl-devel pcre* rrdtool*
三、安装 expat 依赖
cd /root
wget http://jaist.dl.sourceforge.net/project/expat/expat/2.1.0/expat-2.1.0.tar.gz
tar -xf expat-2.1.0.tar.gz && cd expat-2.1.0 && ./configure –prefix=/usr/local/expat && make && make install && cd ..
四、安装 confuse
wget http://ftp.twaren.net/Unix/NonGNU//confuse/confuse-2.7.tar.gz
tar -xf confuse-2.7.tar.gz && cd confuse-2.7 && ./configure CFLAGS=-fPIC –disable-nls –prefix=/usr/local/confuse && make && make install && cd ..
64bit 机器需要拷贝动态链接库:
mkdir -p /usr/local/confuse/lib64 && cp -a -f /usr/local/confuse/lib/* /usr/local/confuse/lib64/
更多详情见请继续阅读下一页的精彩内容:http://www.linuxidc.com/Linux/2017-03/141652p2.htm
七、客户端配置(gmond 节点)
本机安装如下:
cp -f ganglia-3.6.0/gmond/gmond.init /etc/init.d/gmond && cp -f /usr/local/ganglia/sbin/gmond /usr/sbin/gmond && chkconfig –add gmond && gmond –default_config > /etc/ganglia/gmond.conf
对于生成的默认配置文件 /etc/ganglia/gmond.conf 需要做适当的修改
globals {
user = root /* 运行 Ganglia 的用户 */
host_dmax = 120 /*secs */
send_metadata_interval = 15 /* 发送数据的时间间隔 */
}
cluster {
name = “Hadoop” /* 集群名称 */
owner = “root” /* 运行 Ganglia 的用户 */
}
udp_send_channel {
# mcast_join = 239.2.11.71 /* 注释掉组播 */
host = 192.168.1.108/* 发送给安装 gmetad 的机器 */
}
udp_recv_channel {#接受 UDP 包配置
# mcast_join = 239.2.11.71
# bind = 239.2.11.71
}
其中 name 是将要在服务端进行的分组,是服务端的数据源。接下来开启服务
service gmond start
看见 Starting GANGLIA gmetad: [OK]代表启动成功。如果有失败,可以讲 gmond.conf 中的 debug 从 0 改为 100,看更多的日志,然后进行排查。

八、服务端的 WEB 配置
PHP 程序需要依赖 Apache 来运行,因此需要安装如下依赖
yum -y install php httpd
service httpd start // 启动 httpd 服务
九、测试安装是否成功
vi /var/www/html/index.php
输入:
<?php phpinfo();?>
保存,然后浏览器 localhost/index.php
正常是看到 php 的信息。

cd /root
wget http://jaist.dl.sourceforge.net/project/ganglia/ganglia-web/3.5.10/ganglia-web-3.5.10.tar.gz
tar -xf ganglia-web-3.5.10.tar.gz && cd ganglia-web-3.5.10 && make install && cd ..
这样 在 /var/www/html/ 下 生成了 ganglia 目录
注(可能出现的问题):
Ganglia 访问失败:
There was an error collecting ganglia data (127.0.0.1:8652): fsockopen error: Permission denied
解决:
需要关闭 selinux:vi /etc/selinux/config,把 SELINUX=enforcing 改成 SELINUX=disabled;需要重启机器。
可以使用命令 setenforce 0 来关闭 selinux 而不需要重启,刷新页面,即可访问。但此方法只是一权宜之计。要想永久修改 selinux 设置,还是要使用第一种方法。
重启 httpd 服务器即可看到效果
service httpd restart

使用 http://master/ganglia 查看对应的 ganglia 信息。(注:master 为运行 gmetad 的主机的 hostname)
Ganglia 集群配置
免密码登录
单机配置好后,现在来配置集群的:
把刚才配置的那台 VMware 中的虚拟机,使用克隆功能,克隆出两台,然后:
vi /etc/sysconfig/network #修改主机名
vi /etc/hosts #修改主机名和 IP 映射
三台主机 IP、主机名、角色对应关系:

在每台主机中敲入如下命令,然后一直回车确认就可以了,如果是 root 用户,会在 /root/.ssh 目录下生成密钥文件。
ssh-keygen -t rsa

拷贝 slave01 上公钥到 master01 上面(slave02 也需要)

然后通过命令拷贝三台主机公钥到 authorized_keys 文件
在 master01 主机上 /root/.ssh 目录下,slave01 和 slave02 中 id_rsa.pub 也拷贝到这个目录, 并且名称分别为 slave01,slave02
cat id_rsa.pub >> authorized_keys
cat slave01 >> authorized_keys
cat slave02 >> authorized_keys

这时我们就可以免密码登录了

配置并开启 Ganglia 集群
永久关闭 slave01,slave02 上面的 Ganglia 服务端 gmetad

查看 Ganglia 服务端 gmetad 和客户端 gmond 是否都开启

开启 Apache 的 httpd 服务

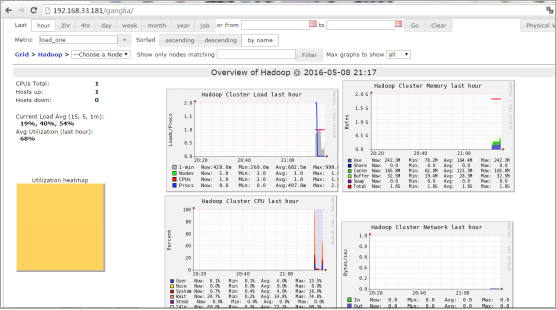
Ganglia 监控图示:

Hadoop 环境软件准备
首先需要将 JDK 以及 Hadoop 软件解压到需要安装的目录
安装 JDK
配置 Java 到环境变量

验证 Java 环境是否安装好

安装 Hadoop
把 Hadoop 添加到环境变量

拷贝 master01 上修改好的 /etc/profile 文件到其他两台主机

使环境变量立即生效

查看 hadoop 版本

建立 data,name,tmp 文件夹:后面配置文件中需要用到

Hadoop 配置文件修改
hadoop-env.sh
在文件头添加如下内容
export JAVA_HOME=/usr/local/jdk1.7.0_80
export HADOOP_LOG_DIR=/usr/local/hadoop_repo/logs
export HADOOP_ROOT_LOGGER=DEBUG,DRFA
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop_repo/tmp</value>
</property>
<!–
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
–>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop_repo/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop_repo/data</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///usr/local/hadoop_repo/namesecondary</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master01:9001</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property><property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/history</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value>
</property>
<property>
<name>mapreduce.map.log.level</name>
<value>DEBUG</value>
</property>
<property>
<name>mapreduce.reduce.log.level</name>
<value>DEBUG</value>
</property>
</configuration>
slaves
master01
slave01
slave02
yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.7.0_80
export YARN_LOG_DIR=/usr/local/hadoop_repo/logs
export YARN_ROOT_LOGGER=DEBUG,DRFA
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master01</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master01:8088</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
Hadoop 集群启动
启动 HDFS
格式化:
![]()
启动 dfs:

master01 上面的 hdfs 进程:

slave01,slave02 上面的 hdfs 进程:

HDFS 的 web 页面:192.168.33.181:50070/

启动 yarn
启动 yarn 命令:
start-yarn.xml

Yarn 的 Web 页面:192.168.33.181:8088
Wordcount 实例运行
Wordcount 实例所在 jar 包位置:
/usr/local/hadoop-2.6.0/share/hadoop/mapreduce

创建一个 words 文件,并写入如下文本:
vi words

通过客户端查看 HDFS 文件系统目录:
hdfs dfs -ls -R /

运行 wordcount 的脚本命令
hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount /input/words /output
HDFS 文件系统路径页面示图:

HDFS 页面查看运行结果目录:

通过 Yarn 的 web 页面查看实例运行状态,如下为实例运行结束的图示:

查看 wordcount 实例的运行结果:
hdfs dfs -text /output/part-r-00000

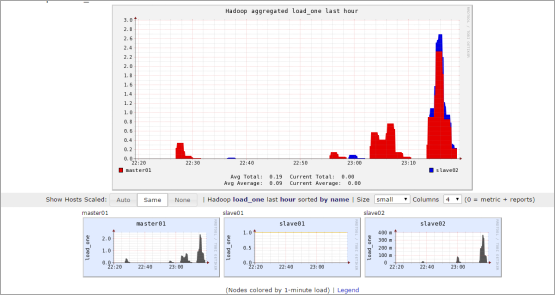
Ganglia 监控 Hadoop 集群图

更多 Hadoop 相关信息见Hadoop 专题页面 http://www.linuxidc.com/topicnews.aspx?tid=13
本文永久更新链接地址:http://www.linuxidc.com/Linux/2017-03/141652.htm















