")

共计 5508 个字符,预计需要花费 14 分钟才能阅读完成。
实验环境
- Ubuntu 16.04
- Hadoop-2.7.3
- Java 7
- SSH
在本篇教程中,我总共使用了两台装有 Ubuntu 16.04 虚拟机,分别称为 master 和 slave。
| IP | 主机名 (hostname) | 内存 | CPU |
|---|---|---|---|
| 192.168.0.161 | hadoop-master | 8192 MB | 4 cores |
| 192.168.0.162 | hadoop-s1 | 8192 MB | 4 cores |
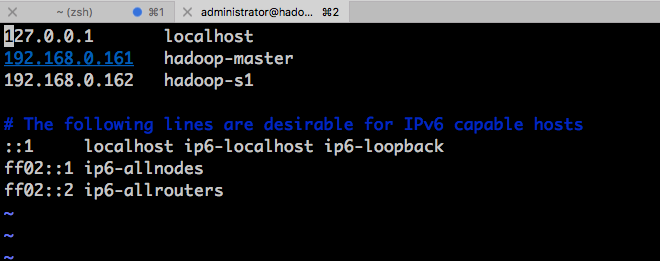
首先需要在两台机器上各自的 /etc/hosts 文件中加上彼此的主机名和 IP 地址:
安装 Java 7
$ sudo add-apt-repository ppa:openjdk-r/ppa
$ sudo apt-get update
$ sudo apt-get install openjdk-7-jdk
$ java -version如果 java 安装成功,那么默认是装在了 /usr/lib/jvm 下的,我们需要把以下的两句加入 ~/.bashrc 中。
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export PATH=$PATH:/usr/lib/jvm/java-7-openjdk-amd64/binSSH 免密登录
Hadoop 需要节点之间可以免密访问,因此我们需要生成 SSH 秘钥并且加入对方的配置文件。
首先在 master 上执行:
$ sudo apt-get install openssh-server
$ ssh-keygen -t rsa -P ""然后把生成的 id_rsa.pub 加入 authorized_keys 里:
$ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys此时 master 已经可以对 localhost 免密访问了
$ ssh localhost接下来,为了使 master 能免密访问 slave:
$ ssh-copy-id -i $HOME/.ssh/id_rsa.pub administrator@hadoop-s1
$ ssh hadoop-s1安装 Hadoop
Hadoop 的各个版本的 Release 版本在 http://hadoop.apache.org/releases.html
在 Master 和 Slave 节点上
下载 hadoop-2.7.3 压缩包,并解压。
$ cd $HOME
$ wget http://mirror.fibergrid.in/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
$ tar -xvf hadoop-2.7.3.tar.gz此时可以通过以下命令确认 hadoop 是否成功安装
$ cd hadoop-2.7.3/
$ bin/hadoop-2.7.3如果成功安装,则把 hadoop 的以下环境变量加入 .bashrc 文件中。
# Set Hadoop-related environment variables
export HADOOP_HOME=$HOME/hadoop-2.7.3
export HADOOP_CONF_DIR=$HOME/hadoop-2.7.3/etc/hadoop
export HADOOP_MAPRED_HOME=$HOME/hadoop-2.7.3
export HADOOP_COMMON_HOME=$HOME/hadoop-2.7.3
export HADOOP_HDFS_HOME=$HOME/hadoop-2.7.3
export YARN_HOME=$HOME/hadoop-2.7.3
# Add Hadoop bin/ directory to PATH
export PATH=$PATH:$HOME/hadoop-2.7.3/bin$ source .bashrc然后将 JAVA_HOME 配置到 hadoop-2.7.3/etc/hadoop/hadoop-env.sh 里,这个文件指定了 Hadoop 的守护进程使用的 JDK 环境变量。
$ cd hadoop-2.7.3/etc/hadoop/
$ sudo vim hadoop-env.sh将以下命令贴到文件中并保存。
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64接下来我们创建 NameNode 和 DataNode 的目录。
$ cd
$ mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/namenode
$ mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/datanodeHadoop 有很多的配置文件需要我们根据需求来做相应的配置,下面一个一个地进行配置。
$ cd hadoop-2.7.3/etc/hadoop/
$ sudo vim core-site.xmlcore-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>hdfs-site.xml
$ sudo vim hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/datanode</value>
</property>
</configuration>yarn-site.xml
$ sudo vim yarn-site.xml<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop-master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop-master:8088</value>
</property>
</configuration>mapred-site.xml
$ cp mapred-site.xml.template mapred-site.xml
$ sudo vim mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx3072m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx3072m</value>
</property>
</configuration>$ sudo vim hadoop-2.7.3/etc/hadoop/mastershadoop-master$ sudo vim hadoop-2.7.3/etc/hadoop/slaveshadoop-master
hadoop-s1现在对 Hadoop 集群 master 的配置已经完成了,我们需要按照同样的步骤配置 slave 节点。当两台机器都安装并配置好 hadoop 之后,我们就可以启动 hadoop 集群了。首先要格式化 hadoop 的文件系统。
On Master
$ cd hadoop-2.7.3/bin
$ hadoop namenode -format然后就可以启动 Hadoop 的守护进程了(NameNode, DataNode, ResourceManager 和 NodeManager)
$ cd ..
$ sbin/start-dfs.sh运行完成后再启动 yarn。
$ sbin/start-yarn.sh通过在命令行运行 jps 指令我们可以看到当前运行在 master 节点上的守护进程。


此时可在 hadoop-master 节点上访问 http://hadoop-master:8088/cluster/nodes 和 http://hadoop-master:50070/dfshealth.html 来查看集群的一些状态信息。

运行 MapReduce 示例程序做词频统计
Hadoop 中的所有 MapReduce 都是运行在 HDFS 上的。首先我们可以去网上随便找一篇莎士比亚全集,用 txt 格式保存在某个目录中,本文是保存在 master 的 $HOME 下,文件大小为 54MB。
把用来做词频统计的输入文件放到 HDFS 中,就可以运行 wordcount 来做词频统计了。
$ cd $HADOOP_HOME
$ hdfs dfs -put $HOME/shakespeare.txt /input
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-example-2.7.3.jar wordcount /input /output程序运行起来后可以在 http://hadoop-master:8088/cluster/nodes 查看任务的状态。如果运行成功,统计结果会存在 HDFS 的 /output 目录下。如果想查看的话可以从 HDFS 中导入到本地的文件系统。
hdfs dfs -getmerge /output $HOME/output.txt如果想了解更多对 HDFS 的操作方式,可以访问 https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/FileSystemShell.html#Overview
Hadoop2.3-HA 高可用集群环境搭建 http://www.linuxidc.com/Linux/2017-03/142155.htm
Hadoop 项目之基于 CentOS7 的 Cloudera 5.10.1(CDH)的安装部署 http://www.linuxidc.com/Linux/2017-04/143095.htm
Hadoop2.7.2 集群搭建详解(高可用)http://www.linuxidc.com/Linux/2017-03/142052.htm
使用 Ambari 来部署 Hadoop 集群(搭建内网 HDP 源)http://www.linuxidc.com/Linux/2017-03/142136.htm
Ubuntu 14.04 下 Hadoop 集群安装 http://www.linuxidc.com/Linux/2017-02/140783.htm
CentOS 7 下 Hadoop 2.6.4 分布式集群环境搭建 http://www.linuxidc.com/Linux/2017-06/144932.htm
Hadoop2.7.3+Spark2.1.0 完全分布式集群搭建过程 http://www.linuxidc.com/Linux/2017-06/144926.htm
更多 Hadoop 相关信息见Hadoop 专题页面 http://www.linuxidc.com/topicnews.aspx?tid=13
本文永久更新链接地址:http://www.linuxidc.com/Linux/2017-07/145503.htm














