")

共计 12145 个字符,预计需要花费 31 分钟才能阅读完成。
无论是甲方还是一方都需要面对大量日志处理的情况,之前分析的时候用基本的 shell 命令进行处理,但是面对大量数据的时候则有些力不从心,而且面对纯文字也不大直观。后来有人推荐了 ELK,最近 ELK 升级到了版本五。E,L,K 三大组件统一了版本号,花了一段时间总算搭好了。
基本环境信息:
Linux 操作系统:CentOS 6.9 x64
Java 版本号:1.8.0_131
ELK: 5.5
0×01 安装 java
ELK 需要最新的 java1.8.CentOS 自带了 openjdk1.7, 删了重新安装 Oracle Java
yum remove java
然后从 oracle 官网 (http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) 下载 java 的源码包
| mkdir /usr/java | |
| tar -zxvf jdk-8u131-linux-x64.tar.gz -C /usr/java/ |
编辑 /etc/profile
| JAVA_HOME=/usr/java/jdk1.8.0_131 | |
| JRE_HOME=/usr/java/jdk1.8.0_131/jre | |
| PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin | |
| CLASSPATH=:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib | |
| export PATH=$PATH:$JAVA_HOME:$JRE_HOME:$CLASSPATH |
创建 java 的软连接
| cd /usr/bin | |
| ln -s /usr/java/jdk1.8.0_131/bin/java java |
如图,安装成功

2. 安装 elasticsearch
Elasticsearch 教程系列文章:
Linux 上安装部署 ElasticSearch 全程记录 http://www.linuxidc.com/Linux/2015-09/123241.htm
Linux 下 Elasticsearch 1.7.0 安装配置 http://www.linuxidc.com/Linux/2017-05/144215.htm
Elasticsearch 的安装,运行和基本配置 http://www.linuxidc.com/Linux/2016-07/133057.htm
使用 Elasticsearch + Logstash + Kibana 搭建日志集中分析平台实践 http://www.linuxidc.com/Linux/2015-12/126587.htm
Ubuntu 14.04 搭建 ELK 日志分析系统(Elasticsearch+Logstash+Kibana) http://www.linuxidc.com/Linux/2016-06/132618.htm
Elasticsearch1.7 升级到 2.3 实践总结 http://www.linuxidc.com/Linux/2016-11/137282.htm
Ubuntu 14.04 中 Elasticsearch 集群配置 http://www.linuxidc.com/Linux/2017-01/139460.htm
Elasticsearch-5.0.0 移植到 Ubuntu 16.04 http://www.linuxidc.com/Linux/2017-01/139505.htm
ElasticSearch 5.2.2 集群环境的搭建 http://www.linuxidc.com/Linux/2017-04/143136.htm
Linux 下安装搜索引擎 Elasticsearch http://www.linuxidc.com/Linux/2017-05/144105.htm
CentOS 上安装 ElasticSearch 详解 http://www.linuxidc.com/Linux/2017-05/143766.htm
在 Ubuntu 16.04 中安装 Elasticsearch 5.4 分析引擎 http://www.linuxidc.com/Linux/2017-07/145588.htm
去 elk 官网下载 elasticsearch 的 rpm 包,

直接安装
rpm -ivh elasticsearch-5.5.0.rpm
启动测试
/etc/init.d/elasticsearch start
如图,安装成功

清空 elasticsearch 的数据
curl -XDELETE 'http://127.0.0.1:9200/logstash-*'
配置一下权限
cd /var/lib
chmod -R 777 logstash
3. 安装 kibana
还是从官网下载 kibana 的二进制包
rpm -ivh kibana-5.5.0-x86_64.rpm
启动
/etc/init.d/kibana start

如图所示,kibaba 也安装成功了, 现在 kibana 只能从本地访问,为了方便调试,利用 nginx 做一下反向代理
| yum install nginx | |
| #/etc/nginx/conf.d/default.conf | |
| server {listen 80; | |
| location / {proxy_pass [http://localhost:5601](http://localhost:5601); | |
| } | |
| } |
4. 安装 logstash
安装 logstash 和之前的步骤一样, 但是 logstash 是没有独立的守护服务的
安装后的路径
/usr/share/logstash/
创建 config 的软连接
| cd /usr/share/logstash | |
| ln -s /etc/logstash ./config |
Logstash 配置文件是 JSON 格式,放在 /etc/logstash/conf.d。该配置由三个部分组成:输入,过滤器和输出。
input 数据输入端,可以接收来自任何地方的源数据。
file:从文件中读取
syslog:监听在 514 端口的系统日志信息,并解析成 RFC3164 格式。
redis:从 redis-server list 中获取
beat:接收来自 Filebeat 的事件
Filter 数据中转层,主要进行格式处理,数据类型转换、数据过滤、字段添加,修改等,常用的过滤器如下。
grok: 通过正则解析和结构化任何文本。Grok 目前是 logstash 最好的方式对非结构化日志数据解析成结构化和可查询化。logstash 内置了 120 个匹配模式,满足大部分需求。
mutate: 在事件字段执行一般的转换。可以重命名、删除、替换和修改事件字段。
drop: 完全丢弃事件,如 debug 事件。
clone: 复制事件,可能添加或者删除字段。
geoip: 添加有关 IP 地址地理位置信息。
output 是 logstash 工作的最后一个阶段,负责将数据输出到指定位置,兼容大多数应用,常用的有:
elasticsearch: 发送事件数据到 Elasticsearch,便于查询,分析,绘图。
file: 将事件数据写入到磁盘文件上。
mongodb: 将事件数据发送至高性能 NoSQL mongodb,便于永久存储,查询,分析,大数据分片。
redis: 将数据发送至 redis-server,常用于中间层暂时缓存。
graphite: 发送事件数据到 graphite。http://graphite.wikidot.com/
statsd: 发送事件数据到 statsd。
其中 input 和 output 是必须的,logstash 由一个 e 参数,可以在终端调试配置文件
最简单的输入输出
/usr/share/logstash/bin# ./logstash -e 'input {stdin {} } output {stdout {} }'

采用格式化输出
logstash -e 'input {stdin {} } output {stdout { codec => rubydebug} }'

这边,我们是从终端输入,同时也从终端输出,但在实际状况中几乎不可能这么做,那先打通输出环节吧,把输出的内容发送到
Elasticsearch
首先启动 Elasticsearch,确保 9200 端口开着,前边已经启动了。然后执行
./logstash -e 'input {stdin {} } output {elasticsearch { hosts => localhost} }'

确认一下
curl 'http://localhost:9200/_search?pretty'

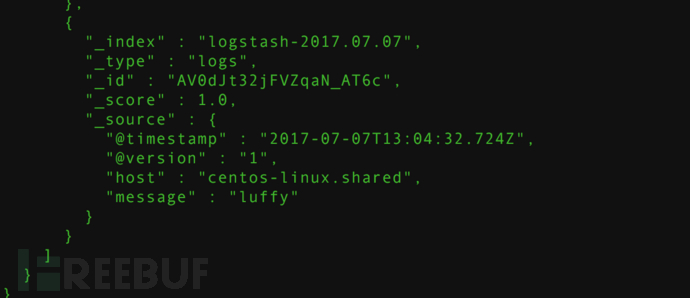
logstash 的 e 参数调试是很方便,但是内容多的话就不方便了,logstash 还有一个 f 参数,用来从配置文件中读取信息, 简单示例
| #logstash_simple.conf | |
| input {stdin {} } | |
| output {elasticsearch { hosts => localhost} | |
| } | |
| # ./logstash -f ../config/logstash_simple.conf | |
|  | |
|  | |
| 然后说一下过滤器 | |
| #logstash.conf | |
| input {stdin {} } | |
| filter { grok { | |
| match => ["message", "%{COMBINEDAPACHELOG}"] | |
| } | |
| } | |
| output {elasticsearch { hosts => localhost} | |
| } |
filter 以何种规则从字符串中提取出结构化的信息,grok 是 logstash 里的一款插件,可以使用正则表达式匹配日志,上文中的 %{COMBINEDAPACHELOG}是内置的正则,用来匹配 apache access 日志.
测试信息
127.0.0.1 - - [11/Dec/2013:00:01:45 -0800] "GET /xampp/status.php HTTP/1.1" 200 3891 "http://cadenza/xampp/navi.php" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0"

curl 'http://localhost:9200/_search?pretty'

分析本地的 apache 日志文件
首先启动 elasticsearch
/etc/init.d/elasticsearch start
然后创建 logstash 的 json 文件
| #logstash_apache.conf | |
| input {file {path => "/tmp/access.log" | |
| type => "apache" | |
| start_position => "beginning" | |
| } | |
| } | |
| filter {grok { | |
| match => {"message" => "%{COMBINEDAPACHELOG}" | |
| } | |
| } | |
| date {match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z"] | |
| } | |
| } | |
| output {elasticsearch {hosts => localhost} | |
| } |
启动 logstash
./logstash -f ../config/logstash_apache.conf

根据日志的时间修改一下时间段

然后是我最喜欢的功能,基于 IP 的地理位置显示

更多详情见请继续阅读下一页的精彩内容:http://www.linuxidc.com/Linux/2017-07/145636p2.htm
5. 利用 filebeat 和 redis 搭建实时分析环境
下载安装 redis
| yum install redis | |
| /etc/init.d/redis start |
filebeat 从官网下载 rpm 包直接安装即可
在 filebeat 中,/var/lib/filebeat/registry 是文件读取的记录,为了让 filebeat 从头开始读,把他删了
修改 filebeat 配置文件
| filebeat.prospectors: | |
| - type: log | |
| paths: | |
| - /var/log/httpd/access_log | |
| tail_files: false | |
| #- input_type: log | |
| # paths: | |
| # - /var/log/nginx/*.log | |
| # encoding: utf-8 | |
| # document_type: my-nginx-log | |
| # scan_frequency: 10s | |
| # harvester_buffer_size: 16384 | |
| # max_bytes: 10485760 | |
| # tail_files: | |
| output.redis: | |
| enabled: true | |
| hosts: ["127.0.0.1:6379"] | |
| key: "filebeat" | |
| db: 0 | |
| worker: 1 | |
| timeout: 5s | |
| max_retries: 3 | |
| #output.console: | |
| # pretty: true |
启动 filebeat
filebeat -e -c /etc/filebeat/shadow.yml

去 redis 检查一下

有 filebeat 证明检查成功
既然 redis 和 filebeat 的通道打通了,然后就是打通 redis 和 elasticsearch
| #/usr/share/logstash/config/logstash_index.conf | |
| input {redis { # 去 redis 队列取数据; | |
| host => "127.0.0.1" # 连接 redis 服务器; | |
| port => 6379 # 连接 redis 端口; | |
| data_type => "list" # 数据类型; | |
| key => "filebeat" # 队列名称; | |
| batch_count => 1 | |
| } | |
| } | |
| filter { | |
| grok {match => ["message", "%{COMBINEDAPACHELOG}"] | |
| } | |
| date {match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ] | |
| } | |
| } | |
| output {elasticsearch { #Logstash 输出到 elasticsearch; | |
| hosts => ["localhost:9200"] #elasticsearch 为本地; | |
| index => "logstash-apache-%{+YYYY.MM.dd}" # 创建索引; | |
| document_type => "apache" # 文档类型; | |
| workers => 1 # 进程数量; | |
| flush_size => 20000 | |
| idle_flush_time => 10 | |
| } | |
| #stdout{codec => rubydebug} | |
| } |
./logstash -f ../config/logstash_index.conf

访问一下 apache 服务器,请求变成了 6 个


6. 配置守护进程
每次启动的程序和服务太多了,为了避免麻烦用 supervisor 放到后台
yum install supervisor
写配置文件
| #/etc/supervisord.conf | |
| [program:iptables] | |
| command=/etc/init.d/iptables stop | |
| user=root | |
| stdout_logfile=/tmp/elk/iptables.log | |
| [program:nginx] | |
| command=nginx | |
| user=root | |
| stdout_logfile=/tmp/elk/nginx.log | |
| [program:redis] | |
| command=/etc/init.d/redis start | |
| user=root | |
| stdout_logfile=/tmp/elk/redis.log | |
| [program:kibana] | |
| command=/etc/init.d/kibana start | |
| user=root | |
| stdout_logfile=/tmp/elk/kibana.log | |
| stderr_logfile=/tmp/elk/kibana_error.log | |
| [program:filebeat] | |
| command=/usr/share/filebeat/bin/filebeat -c /etc/filebeat/shadow.yml | |
| user=root | |
| stdout_logfile=/tmp/elk/filebeat.log | |
| [program:logstash] | |
| command=/usr/share/logstash/bin/logstash -f /usr/share/logstash/config/logstash_index.conf | |
| user=root | |
| stdout_logfile=/tmp/elk/logstash.log | |
| [program:elasticsearch] | |
| command=/etc/init.d/elasticsearch start | |
| user=root | |
| stdout_logfile=/tmp/elk/elasticsearch.log | |
| stderr_logfile=/tmp/elk/ela_err.log | |
| [supervisord] |
开机一条命令搞定
supervisord -c /etc/supervisord.conf
Linux 日志分析 ELK 环境搭建 http://www.linuxidc.com/Linux/2017-07/145494.htm
完整 PDF 文档可以到 Linux 公社资源站下载:
—————————————— 分割线 ——————————————
免费下载地址在 http://linux.linuxidc.com/
用户名与密码都是www.linuxidc.com
具体下载目录在 /2017 年资料 / 7 月 /13 日 / 基于 CentOS 6.9 搭建 ELK 环境指南 /
下载方法见 http://www.linuxidc.com/Linux/2013-07/87684.htm
—————————————— 分割线 ——————————————
本文永久更新链接地址 :http://www.linuxidc.com/Linux/2017-07/145636.htm
无论是甲方还是一方都需要面对大量日志处理的情况,之前分析的时候用基本的 shell 命令进行处理,但是面对大量数据的时候则有些力不从心,而且面对纯文字也不大直观。后来有人推荐了 ELK,最近 ELK 升级到了版本五。E,L,K 三大组件统一了版本号,花了一段时间总算搭好了。
基本环境信息:
Linux 操作系统:CentOS 6.9 x64
Java 版本号:1.8.0_131
ELK: 5.5
0×01 安装 java
ELK 需要最新的 java1.8.CentOS 自带了 openjdk1.7, 删了重新安装 Oracle Java
yum remove java
然后从 oracle 官网 (http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) 下载 java 的源码包
| mkdir /usr/java | |
| tar -zxvf jdk-8u131-linux-x64.tar.gz -C /usr/java/ |
编辑 /etc/profile
| JAVA_HOME=/usr/java/jdk1.8.0_131 | |
| JRE_HOME=/usr/java/jdk1.8.0_131/jre | |
| PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin | |
| CLASSPATH=:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib | |
| export PATH=$PATH:$JAVA_HOME:$JRE_HOME:$CLASSPATH |
创建 java 的软连接
| cd /usr/bin | |
| ln -s /usr/java/jdk1.8.0_131/bin/java java |
如图,安装成功
2. 安装 elasticsearch
Elasticsearch 教程系列文章:
Linux 上安装部署 ElasticSearch 全程记录 http://www.linuxidc.com/Linux/2015-09/123241.htm
Linux 下 Elasticsearch 1.7.0 安装配置 http://www.linuxidc.com/Linux/2017-05/144215.htm
Elasticsearch 的安装,运行和基本配置 http://www.linuxidc.com/Linux/2016-07/133057.htm
使用 Elasticsearch + Logstash + Kibana 搭建日志集中分析平台实践 http://www.linuxidc.com/Linux/2015-12/126587.htm
Ubuntu 14.04 搭建 ELK 日志分析系统(Elasticsearch+Logstash+Kibana) http://www.linuxidc.com/Linux/2016-06/132618.htm
Elasticsearch1.7 升级到 2.3 实践总结 http://www.linuxidc.com/Linux/2016-11/137282.htm
Ubuntu 14.04 中 Elasticsearch 集群配置 http://www.linuxidc.com/Linux/2017-01/139460.htm
Elasticsearch-5.0.0 移植到 Ubuntu 16.04 http://www.linuxidc.com/Linux/2017-01/139505.htm
ElasticSearch 5.2.2 集群环境的搭建 http://www.linuxidc.com/Linux/2017-04/143136.htm
Linux 下安装搜索引擎 Elasticsearch http://www.linuxidc.com/Linux/2017-05/144105.htm
CentOS 上安装 ElasticSearch 详解 http://www.linuxidc.com/Linux/2017-05/143766.htm
在 Ubuntu 16.04 中安装 Elasticsearch 5.4 分析引擎 http://www.linuxidc.com/Linux/2017-07/145588.htm
去 elk 官网下载 elasticsearch 的 rpm 包,
直接安装
rpm -ivh elasticsearch-5.5.0.rpm
启动测试
/etc/init.d/elasticsearch start
如图,安装成功
清空 elasticsearch 的数据
curl -XDELETE 'http://127.0.0.1:9200/logstash-*'
配置一下权限
cd /var/lib
chmod -R 777 logstash
3. 安装 kibana
还是从官网下载 kibana 的二进制包
rpm -ivh kibana-5.5.0-x86_64.rpm
启动
/etc/init.d/kibana start
如图所示,kibaba 也安装成功了, 现在 kibana 只能从本地访问,为了方便调试,利用 nginx 做一下反向代理
| yum install nginx | |
| #/etc/nginx/conf.d/default.conf | |
| server {listen 80; | |
| location / {proxy_pass [http://localhost:5601](http://localhost:5601); | |
| } | |
| } |
4. 安装 logstash
安装 logstash 和之前的步骤一样, 但是 logstash 是没有独立的守护服务的
安装后的路径
/usr/share/logstash/
创建 config 的软连接
| cd /usr/share/logstash | |
| ln -s /etc/logstash ./config |
Logstash 配置文件是 JSON 格式,放在 /etc/logstash/conf.d。该配置由三个部分组成:输入,过滤器和输出。
input 数据输入端,可以接收来自任何地方的源数据。
file:从文件中读取
syslog:监听在 514 端口的系统日志信息,并解析成 RFC3164 格式。
redis:从 redis-server list 中获取
beat:接收来自 Filebeat 的事件
Filter 数据中转层,主要进行格式处理,数据类型转换、数据过滤、字段添加,修改等,常用的过滤器如下。
grok: 通过正则解析和结构化任何文本。Grok 目前是 logstash 最好的方式对非结构化日志数据解析成结构化和可查询化。logstash 内置了 120 个匹配模式,满足大部分需求。
mutate: 在事件字段执行一般的转换。可以重命名、删除、替换和修改事件字段。
drop: 完全丢弃事件,如 debug 事件。
clone: 复制事件,可能添加或者删除字段。
geoip: 添加有关 IP 地址地理位置信息。
output 是 logstash 工作的最后一个阶段,负责将数据输出到指定位置,兼容大多数应用,常用的有:
elasticsearch: 发送事件数据到 Elasticsearch,便于查询,分析,绘图。
file: 将事件数据写入到磁盘文件上。
mongodb: 将事件数据发送至高性能 NoSQL mongodb,便于永久存储,查询,分析,大数据分片。
redis: 将数据发送至 redis-server,常用于中间层暂时缓存。
graphite: 发送事件数据到 graphite。http://graphite.wikidot.com/
statsd: 发送事件数据到 statsd。
其中 input 和 output 是必须的,logstash 由一个 e 参数,可以在终端调试配置文件
最简单的输入输出
/usr/share/logstash/bin# ./logstash -e 'input {stdin {} } output {stdout {} }'
采用格式化输出
logstash -e 'input {stdin {} } output {stdout { codec => rubydebug} }'
这边,我们是从终端输入,同时也从终端输出,但在实际状况中几乎不可能这么做,那先打通输出环节吧,把输出的内容发送到
Elasticsearch
首先启动 Elasticsearch,确保 9200 端口开着,前边已经启动了。然后执行
./logstash -e 'input {stdin {} } output {elasticsearch { hosts => localhost} }'
确认一下
curl 'http://localhost:9200/_search?pretty'
logstash 的 e 参数调试是很方便,但是内容多的话就不方便了,logstash 还有一个 f 参数,用来从配置文件中读取信息, 简单示例
| #logstash_simple.conf | |
| input {stdin {} } | |
| output {elasticsearch { hosts => localhost} | |
| } | |
| # ./logstash -f ../config/logstash_simple.conf | |
|  | |
|  | |
| 然后说一下过滤器 | |
| #logstash.conf | |
| input {stdin {} } | |
| filter { grok { | |
| match => ["message", "%{COMBINEDAPACHELOG}"] | |
| } | |
| } | |
| output {elasticsearch { hosts => localhost} | |
| } |
filter 以何种规则从字符串中提取出结构化的信息,grok 是 logstash 里的一款插件,可以使用正则表达式匹配日志,上文中的 %{COMBINEDAPACHELOG}是内置的正则,用来匹配 apache access 日志.
测试信息
127.0.0.1 - - [11/Dec/2013:00:01:45 -0800] "GET /xampp/status.php HTTP/1.1" 200 3891 "http://cadenza/xampp/navi.php" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0"
curl 'http://localhost:9200/_search?pretty'
分析本地的 apache 日志文件
首先启动 elasticsearch
/etc/init.d/elasticsearch start
然后创建 logstash 的 json 文件
| #logstash_apache.conf | |
| input {file {path => "/tmp/access.log" | |
| type => "apache" | |
| start_position => "beginning" | |
| } | |
| } | |
| filter {grok { | |
| match => {"message" => "%{COMBINEDAPACHELOG}" | |
| } | |
| } | |
| date {match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z"] | |
| } | |
| } | |
| output {elasticsearch {hosts => localhost} | |
| } |
启动 logstash
./logstash -f ../config/logstash_apache.conf
根据日志的时间修改一下时间段
然后是我最喜欢的功能,基于 IP 的地理位置显示
更多详情见请继续阅读下一页的精彩内容:http://www.linuxidc.com/Linux/2017-07/145636p2.htm














