")

共计 4625 个字符,预计需要花费 12 分钟才能阅读完成。
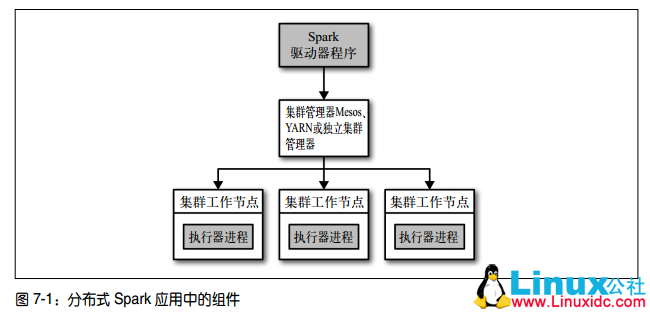
Spark 集群是主从结构。节点分为驱动器(Driver)节点以及执行器(executor)节点。驱动器节点可以和大量的执行器节点进行通信,它们也都作为独立的 Java 进程运行。驱动器节点和所有的执行器节点一起被称为一个 Spark 应用(application)。
驱动器节点
Spark 驱动器是执行程序中的 main() 方法的进程。它执行用户编写的用来创建 SparkContext、创建 RDD,以及进行 RDD 的转化操作和行动操作的代码。当启动 Spark shell 时,就启动了一个 Spark 驱动器程序(Spark shell 总是会预先加载一个叫作 sc 的 SparkContext 对象)。驱动器程序一旦终止,Spark 应用也就结束了。
主要职责
- 把用户程序转为任务:Spark 驱动器程序负责把用户程序转为多个物理执行的单元,这些单元也被称为任务(task)。Spark 会对逻辑执行计划作一些优化,比如将连续的映射转为流水线化执行,将多个操作合并到一个步骤中等。这样 Spark 就把逻辑计划转为一系列步骤(stage)。而每个步骤又由多个任务组成。这些任务会被打包并送到集群中。任务是 Spark 中最小的工作单元,用户程序通常要启动成百上千的独立任务。
- 为执行器节点调度任务:有了物理执行计划之后,Spark 驱动器程序必须在各执行器进程间协调任务的调度。执行器进程启动后,会向驱动器进程注册自己。因此,驱动器进程始终对应用中所有的执行器节点有完整的记录。每个执行器节点代表一个能够处理任务和存储 RDD 数据的进程。Spark 驱动器程序会根据当前的执行器节点集合,尝试把所有任务基于数据所在位置分配给合适的执行器进程。当任务执行时,执行器进程会把缓存数据存储起来,而驱动器进程同样会跟踪这些缓存数据的位置,并且利用这些位置信息来调度以后的任务,以尽量减少数据的网络传输。
执行器节点
工作进程 Spark 应用启动时,执行器节点就被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有执行器节点发生了异常或崩溃,Spark 应用也可以继续执行。
主要职责
- 它们负责运行组成 Spark 应用的任务:并将结果返回给驱动器进程
- 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。 RDD 是直接缓存在执行器进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
集群管理器
Spark 依赖于集群管理器来启动执行器节点,而在某些特殊情况下,也依赖集群管理器来启动驱动器节点。集群管理器是 Spark 中的可插拔式组件。除了 Spark 自带的独立集群管理器,Spark 也可以运行在其他外部集群管理器上,比如 YARN。
不论你使用的是哪一种集群管理器,你都可以使用 Spark 提供的统一脚本 spark-submit 将你的应用提交到那种集群管理器上。通过不同的配置选项,spark-submit 可以连接到相应的集群管理器上,并控制应用所使用的资源数量。
任务的大致执行过程
- 用户通过 spark-submit 脚本提交应用。
- spark-submit 脚本启动驱动器程序,调用用户定义的 main() 方法。
- 驱动器程序与集群管理器通信,申请资源以启动执行器节点。
- 集群管理器为驱动器程序启动执行器节点。
- 驱动器进程执行用户应用中的操作。根据程序中所定义的对 RDD 的转化操作和行动操
作,驱动器节点把工作以任务的形式发送到执行器进程。 - 任务在执行器程序中进行计算并保存结果。
- 如果驱动器程序的 main() 方法退出,或者调用了 SparkContext.stop(),驱动器程序会终止执行器进程,并且通过集群管理器释放资源
spark-submit 的使用
spark-submit 的一些常见的标记如下:

其中的标记后可以接不同的参数,例如对于 –master 可以配置的参数如下表所示:

下面是一些应用部署的例子:
bin/spark-submit [options] <app jar | Python file> [app options]
# 一般的执行格式如上
bin/spark-submit my_script.py
# 本地执行
bin/spark-submit --master spark://host:7077 --executor-memory 10g my_script.py
# --master 标记指定要连接的集群 URL;spark:// 表示集群使用独立模式。稍后会讨论其他的 URL 类型
$ ./bin/spark-submit \
--master spark://hostname:7077 \
--deploy-mode cluster \
--class com.databricks.examples.SparkExample \
--name "Example Program" \
--jars dep1.jar,dep2.jar,dep3.jar \
--total-executor-cores 300 \
--executor-memory 10g \
myApp.jar "options" "to your application" "go here"
# 使用独立集群模式提交 Java 应用
$ export HADOP_CONF_DIR=/opt/Hadoop/conf
$ ./bin/spark-submit \
--master yarn \
--py-files somelib-1.2.egg,otherlib-4.4.zip,other-file.py \
--deploy-mode client \
--name "Example Program" \
# 使用 YARN 客户端模式提交 Python 应用打包代码以及依赖
对于 python:你可以通过标准的 Python 包管理器(比如 pip 和 easy_install)直接在集群中的所有机器上安装所依赖的库,或者把依赖手动安装到 Python 安装目录下的 sitepackages/ 目录中。你也可以使用 spark-submit 的 –py-Files 参数提交独立的库,这样它们也会被添加到 Python 解释器的路径中。如果你没有在集群上安装包的权限,可以手动添加依赖库。
对于 Java 和 Scala:spark-submit 的 –jars 标记提交独立的 JAR 包依赖。当只
有一两个库的简单依赖,并且这些库本身不依赖于其他库时,这种方法比较合适。一
般 Java 和 Scala 的工程会依赖很多库。当你向 Spark 提交应用时,你必须把应用的整个依赖传递图中的所有依赖都传给集群。你不仅要传递你直接依赖的库,还要传递这些库的依
赖,等等。常规的做法是使用构建工具,生成单个大 JAR 包,包含应用的所有的传递依赖。大多数 Java 或 Scala 的构建工具都支持生成这样的工件。例如 java 的 maven 以及 scala 的 sbt。
独立的集群管理器
(1) 将编译好的 Spark 复制到所有机器的一个相同的目录下,比如 /home/yourname/spark。(2) 设置好从主节点机器到其他机器的 SSH 无密码登陆。这需要在所有机器上有相同的用
户账号,并在主节点上通过 ssh-keygen 生成 SSH 私钥,然后将这个私钥放到所有工作
节点的 .ssh/authorized_keys 文件中。如果你之前没有设置过这种配置,你可以使用如下
命令:# 在主节点上:运行 ssh-keygen 并接受默认选项
$ ssh-keygen -t dsa
Enter file in which to save the key (/home/you/.ssh/id_dsa): [回车]
Enter passphrase (empty for no passphrase): [空]
Enter same passphrase again: [空]
# 在工作节点上:# 把主节点的~/.ssh/id_dsa.pub 文件复制到工作节点上,然后使用:$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
$ chmod 644 ~/.ssh/authorized_keys
(3) 编辑主节点的 conf/slaves 文件并填上所有工作节点的主机名。(4) 在主节点上运行 sbin/start-all.sh(要在主节点上运行而不是在工作节点上)以启动集群。如果全部启动成功,你不会得到需要密码的提示符,而且可以在 http://masternode:8080
看到集群管理器的网页用户界面,上面显示着所有的工作节点。(5) 要停止集群,在主节点上运行 bin/stop-all.sh。如果你使用的不是 UNIX 系统,或者想手动启动集群,你也可以使用 Spark 的 bin/ 目录下
的 spark-class 脚本分别手动启动主节点和工作节点。在主节点上,输入:bin/spark-class org.apache.spark.deploy.master.Master
然后在工作节点上输入:bin/spark-class org.apache.spark.deploy.worker.Worker spark://masternode:7077(其中 masternode 是你的主节点的主机名)。在 Windows 中,使用 \ 来代替 /。默认情况下,集群管理器会选择合适的默认值自动为所有工作节点分配 CPU 核心与内
存。配置独立集群管理器的更多细节请参考 Spark 的官方文档(http://spark.apache.org/docs/
latest/spark-standalone.html)更多 Spark 相关教程见以下内容:
CentOS 7.0 下安装并配置 Spark http://www.linuxidc.com/Linux/2015-08/122284.htm
Ubuntu 系统搭建单机 Spark 注意事项 http://www.linuxidc.com/Linux/2017-10/147220.htm
Spark1.0.0 部署指南 http://www.linuxidc.com/Linux/2014-07/104304.htm
Spark2.0 安装配置文档 http://www.linuxidc.com/Linux/2016-09/135352.htm
Spark 1.5、Hadoop 2.7 集群环境搭建 http://www.linuxidc.com/Linux/2016-09/135067.htm
Spark 官方文档 – 中文翻译 http://www.linuxidc.com/Linux/2016-04/130621.htm
CentOS 6.2(64 位)下安装 Spark0.8.0 详细记录 http://www.linuxidc.com/Linux/2014-06/102583.htm
Spark-2.2.0 安装和部署详解 http://www.linuxidc.com/Linux/2017-08/146215.htm
Spark2.0.2 Hadoop2.6.4 全分布式配置详解 http://www.linuxidc.com/Linux/2016-11/137367.htm
Ubuntu 14.04 LTS 安装 Spark 1.6.0(伪分布式)http://www.linuxidc.com/Linux/2016-03/129068.htm
Spark 的详细介绍:请点这里
Spark 的下载地址:请点这里
本文永久更新链接地址:http://www.linuxidc.com/Linux/2017-10/147605.htm













