")

共计 17911 个字符,预计需要花费 45 分钟才能阅读完成。
1. 开发环境:
Windows 2008 64bit
Java 1.6.0_30
MyEclipse 6.5
环境部署见:http://www.linuxidc.com/Linux/2014-02/96528.htm
2.Hadoop 集群环境:
Oracle Linux Enterprise 5.9
Java 1.6.0_18
Hadoop:hadoop 1.2.1 三节点
namenode:10.1.32.91
datanode:10.1.32.93
datanode:10.1.32.95
环境部署见:http://www.linuxidc.com/Linux/2014-02/96529.htm
3. 各 java 类功能介绍:
Recommend.java,主任务启动程序
Step1.java,按用户分组,计算所有物品出现的组合列表,得到用户对物品的评分矩阵
Step2.java,对物品组合列表进行计数,建立物品的同现矩阵
Step3.java,对同现矩阵和评分矩阵转型
Step4.java,合并矩阵,并计算推荐结果列表
HdfsDAO.java,HDFS 操作工具类

4. 执行代码和运行结果:
Recommend.java 代码:
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.hadoop.mapred.JobConf;
public class Recommend {
public static final String HDFS = “hdfs://10.1.32.91:9000”;
public static final Pattern DELIMITER = Pattern.compile(“[\t,]”);
public static void main(String[] args) throws Exception {
Map<String, String> path = new HashMap<String, String>();
path.put(“data”, “C:\\Users\\licz\\workspace\\Mapreduce1\\small2.csv”);
path.put(“Step1Input”, HDFS + “/user/hdfs/recommend”);
path.put(“Step1Output”, path.get(“Step1Input”) + “/step1”);
path.put(“Step2Input”, path.get(“Step1Output”));
path.put(“Step2Output”, path.get(“Step1Input”) + “/step2”);
path.put(“Step3Input1”, path.get(“Step1Output”));
path.put(“Step3Output1”, path.get(“Step1Input”) + “/step3_1”);
path.put(“Step3Input2”, path.get(“Step2Output”));
path.put(“Step3Output2”, path.get(“Step1Input”) + “/step3_2”);
path.put(“Step4Input1”, path.get(“Step3Output1”));
path.put(“Step4Input2”, path.get(“Step3Output2”));
path.put(“Step4Output”, path.get(“Step1Input”) + “/step4”);
Step1.run(path);
Step2.run(path);
Step3.run1(path);
Step3.run2(path);
Step4.run(path);
System.exit(0);
}
public static JobConf config() {
JobConf conf = new JobConf(Recommend.class);
conf.setJobName(“Recommand”);
conf.addResource(“classpath:/hadoop/core-site.xml”);
conf.addResource(“classpath:/hadoop/hdfs-site.xml”);
conf.addResource(“classpath:/hadoop/mapred-site.xml”);
//conf.set(“io.sort.mb”, “1024”);
return conf;
}
}
Step1.java 代码:
import java.io.IOException;
import java.util.Iterator;
import java.util.Map;
import org.apache.Hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.RunningJob;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class Step1 {
public static class Step1_ToItemPreMapper extends MapReduceBase implements Mapper<Object, Text, IntWritable, Text> {
private final static IntWritable k = new IntWritable();
private final static Text v = new Text();
public void map(Object key, Text value, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException {
String[] tokens = Recommend.DELIMITER.split(value.toString());
int userID = Integer.parseInt(tokens[0]);
String itemID = tokens[1];
String pref = tokens[2];
k.set(userID);
v.set(itemID + “:” + pref);
output.collect(k, v);
}
}
public static class Step1_ToUserVectorReducer extends MapReduceBase implements Reducer<IntWritable, Text, IntWritable, Text> {
private final static Text v = new Text();
public void reduce(IntWritable key, Iterator<Text> values, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException {
StringBuilder sb = new StringBuilder();
while (values.hasNext()) {
sb.append(“,” + values.next());
}
v.set(sb.toString().replaceFirst(“,”, “”));
output.collect(key, v);
}
}
public static void run(Map<String, String> path) throws IOException {
JobConf conf = Recommend.config();
String input = path.get(“Step1Input”);
String output = path.get(“Step1Output”);
HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf);
// hdfs.rmr(output);
hdfs.rmr(input);
hdfs.mkdirs(input);
hdfs.copyFile(path.get(“data”), input);
conf.setMapOutputKeyClass(IntWritable.class);
conf.setMapOutputValueClass(Text.class);
conf.setOutputKeyClass(IntWritable.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(Step1_ToItemPreMapper.class);
conf.setCombinerClass(Step1_ToUserVectorReducer.class);
conf.setReducerClass(Step1_ToUserVectorReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
RunningJob job = JobClient.runJob(conf);
while (!job.isComplete()) {
job.waitForCompletion();
}
}
}
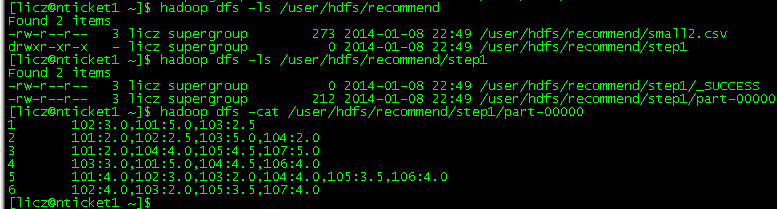
Step1 运行结果:
1. 开发环境:
Windows 2008 64bit
Java 1.6.0_30
MyEclipse 6.5
环境部署见:http://www.linuxidc.com/Linux/2014-02/96528.htm
2.Hadoop 集群环境:
Oracle Linux Enterprise 5.9
Java 1.6.0_18
Hadoop:hadoop 1.2.1 三节点
namenode:10.1.32.91
datanode:10.1.32.93
datanode:10.1.32.95
环境部署见:http://www.linuxidc.com/Linux/2014-02/96529.htm
3. 各 java 类功能介绍:
Recommend.java,主任务启动程序
Step1.java,按用户分组,计算所有物品出现的组合列表,得到用户对物品的评分矩阵
Step2.java,对物品组合列表进行计数,建立物品的同现矩阵
Step3.java,对同现矩阵和评分矩阵转型
Step4.java,合并矩阵,并计算推荐结果列表
HdfsDAO.java,HDFS 操作工具类
4. 执行代码和运行结果:
Recommend.java 代码:
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.hadoop.mapred.JobConf;
public class Recommend {
public static final String HDFS = “hdfs://10.1.32.91:9000”;
public static final Pattern DELIMITER = Pattern.compile(“[\t,]”);
public static void main(String[] args) throws Exception {
Map<String, String> path = new HashMap<String, String>();
path.put(“data”, “C:\\Users\\licz\\workspace\\Mapreduce1\\small2.csv”);
path.put(“Step1Input”, HDFS + “/user/hdfs/recommend”);
path.put(“Step1Output”, path.get(“Step1Input”) + “/step1”);
path.put(“Step2Input”, path.get(“Step1Output”));
path.put(“Step2Output”, path.get(“Step1Input”) + “/step2”);
path.put(“Step3Input1”, path.get(“Step1Output”));
path.put(“Step3Output1”, path.get(“Step1Input”) + “/step3_1”);
path.put(“Step3Input2”, path.get(“Step2Output”));
path.put(“Step3Output2”, path.get(“Step1Input”) + “/step3_2”);
path.put(“Step4Input1”, path.get(“Step3Output1”));
path.put(“Step4Input2”, path.get(“Step3Output2”));
path.put(“Step4Output”, path.get(“Step1Input”) + “/step4”);
Step1.run(path);
Step2.run(path);
Step3.run1(path);
Step3.run2(path);
Step4.run(path);
System.exit(0);
}
public static JobConf config() {
JobConf conf = new JobConf(Recommend.class);
conf.setJobName(“Recommand”);
conf.addResource(“classpath:/hadoop/core-site.xml”);
conf.addResource(“classpath:/hadoop/hdfs-site.xml”);
conf.addResource(“classpath:/hadoop/mapred-site.xml”);
//conf.set(“io.sort.mb”, “1024”);
return conf;
}
}
Step2.java 代码:
import java.io.IOException;
import java.util.Iterator;
import java.util.Map;
import org.apache.Hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.RunningJob;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class Step2 {
public static class Step2_UserVectorToCooccurrenceMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static Text k = new Text();
private final static IntWritable v = new IntWritable(1);
public void map(LongWritable key, Text values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String[] tokens = Recommend.DELIMITER.split(values.toString());
for (int i = 1; i < tokens.length; i++) {
String itemID = tokens[i].split(“:”)[0];
for (int j = 1; j < tokens.length; j++) {
String itemID2 = tokens[j].split(“:”)[0];
k.set(itemID + “:” + itemID2);
output.collect(k, v);
}
}
}
}
public static class Step2_UserVectorToConoccurrenceReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
result.set(sum);
output.collect(key, result);
}
}
public static void run(Map<String, String> path) throws IOException {
JobConf conf = Recommend.config();
String input = path.get(“Step2Input”);
String output = path.get(“Step2Output”);
HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf);
hdfs.rmr(output);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Step2_UserVectorToCooccurrenceMapper.class);
// conf.setCombinerClass(Step2_UserVectorToConoccurrenceReducer.class);
// conf.setReducerClass(Step2_UserVectorToConoccurrenceReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
RunningJob job = JobClient.runJob(conf);
while (!job.isComplete()) {
job.waitForCompletion();
}
}
}
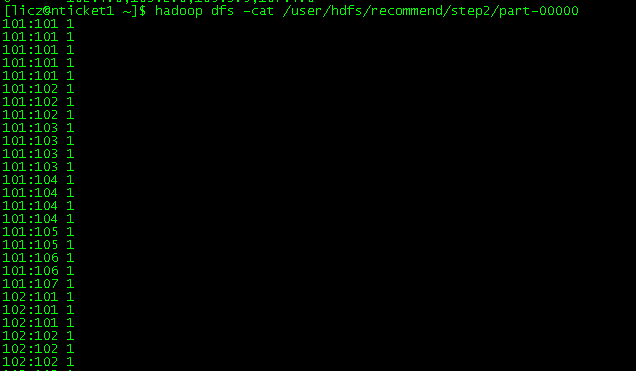
Step2 运行结果:
Step3.java 代码:
import java.io.IOException;
import java.util.Map;
import org.apache.Hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.RunningJob;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class Step3 {
public static class Step31_UserVectorSplitterMapper extends MapReduceBase implements Mapper<LongWritable, Text, IntWritable, Text> {
private final static IntWritable k = new IntWritable();
private final static Text v = new Text();
public void map(LongWritable key, Text values, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException {
String[] tokens = Recommend.DELIMITER.split(values.toString());
for (int i = 1; i < tokens.length; i++) {
String[] vector = tokens[i].split(“:”);
int itemID = Integer.parseInt(vector[0]);
String pref = vector[1];
k.set(itemID);
v.set(tokens[0] + “:” + pref);
output.collect(k, v);
}
}
}
public static void run1(Map<String, String> path) throws IOException {
JobConf conf = Recommend.config();
String input = path.get(“Step3Input1”);
String output = path.get(“Step3Output1”);
HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf);
hdfs.rmr(output);
conf.setOutputKeyClass(IntWritable.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(Step31_UserVectorSplitterMapper.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
RunningJob job = JobClient.runJob(conf);
while (!job.isComplete()) {
job.waitForCompletion();
}
}
public static class Step32_CooccurrenceColumnWrapperMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static Text k = new Text();
private final static IntWritable v = new IntWritable();
public void map(LongWritable key, Text values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String[] tokens = Recommend.DELIMITER.split(values.toString());
k.set(tokens[0]);
v.set(Integer.parseInt(tokens[1]));
output.collect(k, v);
}
}
public static void run2(Map<String, String> path) throws IOException {
JobConf conf = Recommend.config();
String input = path.get(“Step3Input2”);
String output = path.get(“Step3Output2”);
HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf);
hdfs.rmr(output);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Step32_CooccurrenceColumnWrapperMapper.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
RunningJob job = JobClient.runJob(conf);
while (!job.isComplete()) {
job.waitForCompletion();
}
}
}
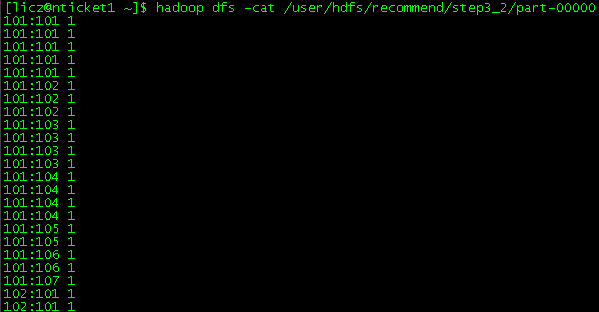
Step3 运行结果:

Step4.java 代码:
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import org.apache.Hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.RunningJob;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class Step4 {
public static class Step4_PartialMultiplyMapper extends MapReduceBase implements Mapper<LongWritable, Text, IntWritable, Text> {
private final static IntWritable k = new IntWritable();
private final static Text v = new Text();
private final static Map<Integer, List<Cooccurrence>> cooccurrenceMatrix = new HashMap<Integer, List<Cooccurrence>>();
public void map(LongWritable key, Text values, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException {
String[] tokens = Recommend.DELIMITER.split(values.toString());
String[] v1 = tokens[0].split(“:”);
String[] v2 = tokens[1].split(“:”);
if (v1.length > 1) {// cooccurrence
int itemID1 = Integer.parseInt(v1[0]);
int itemID2 = Integer.parseInt(v1[1]);
int num = Integer.parseInt(tokens[1]);
List<Cooccurrence> list = null;
if (!cooccurrenceMatrix.containsKey(itemID1)) {
list = new ArrayList<Cooccurrence>();
} else {
list = cooccurrenceMatrix.get(itemID1);
}
list.add(new Cooccurrence(itemID1, itemID2, num));
cooccurrenceMatrix.put(itemID1, list);
}
if (v2.length > 1) {// userVector
int itemID = Integer.parseInt(tokens[0]);
int userID = Integer.parseInt(v2[0]);
double pref = Double.parseDouble(v2[1]);
k.set(userID);
for (Cooccurrence co : cooccurrenceMatrix.get(itemID)) {
v.set(co.getItemID2() + “,” + pref * co.getNum());
output.collect(k, v);
}
}
}
}
public static class Step4_AggregateAndRecommendReducer extends MapReduceBase implements Reducer<IntWritable, Text, IntWritable, Text> {
private final static Text v = new Text();
public void reduce(IntWritable key, Iterator<Text> values, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException {
Map<String, Double> result = new HashMap<String, Double>();
while (values.hasNext()) {
String[] str = values.next().toString().split(“,”);
if (result.containsKey(str[0])) {
result.put(str[0], result.get(str[0]) + Double.parseDouble(str[1]));
} else {
result.put(str[0], Double.parseDouble(str[1]));
}
}
Iterator<String> iter = result.keySet().iterator();
while (iter.hasNext()) {
String itemID = iter.next();
double score = result.get(itemID);
v.set(itemID + “,” + score);
output.collect(key, v);
}
}
}
public static void run(Map<String, String> path) throws IOException {
JobConf conf = Recommend.config();
String input1 = path.get(“Step4Input1”);
String input2 = path.get(“Step4Input2”);
String output = path.get(“Step4Output”);
HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf);
hdfs.rmr(output);
conf.setOutputKeyClass(IntWritable.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(Step4_PartialMultiplyMapper.class);
conf.setCombinerClass(Step4_AggregateAndRecommendReducer.class);
conf.setReducerClass(Step4_AggregateAndRecommendReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input1), new Path(input2));
FileOutputFormat.setOutputPath(conf, new Path(output));
RunningJob job = JobClient.runJob(conf);
while (!job.isComplete()) {
job.waitForCompletion();
}
}
}
class Cooccurrence {
private int itemID1;
private int itemID2;
private int num;
public Cooccurrence(int itemID1, int itemID2, int num) {
super();
this.itemID1 = itemID1;
this.itemID2 = itemID2;
this.num = num;
}
public int getItemID1() {
return itemID1;
}
public void setItemID1(int itemID1) {
this.itemID1 = itemID1;
}
public int getItemID2() {
return itemID2;
}
public void setItemID2(int itemID2) {
this.itemID2 = itemID2;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
}
Step4 运行结果:

相关阅读 :
Ubuntu 13.04 上搭建 Hadoop 环境 http://www.linuxidc.com/Linux/2013-06/86106.htm
Ubuntu 12.10 +Hadoop 1.2.1 版本集群配置 http://www.linuxidc.com/Linux/2013-09/90600.htm
Ubuntu 上搭建 Hadoop 环境(单机模式 + 伪分布模式)http://www.linuxidc.com/Linux/2013-01/77681.htm
Ubuntu 下 Hadoop 环境的配置 http://www.linuxidc.com/Linux/2012-11/74539.htm
单机版搭建 Hadoop 环境图文教程详解 http://www.linuxidc.com/Linux/2012-02/53927.htm
搭建 Hadoop 环境(在 Winodws 环境下用虚拟机虚拟两个 Ubuntu 系统进行搭建)http://www.linuxidc.com/Linux/2011-12/48894.htm
更多 Hadoop 相关信息见 Hadoop 专题页面 http://www.linuxidc.com/topicnews.aspx?tid=13















