")

共计 3401 个字符,预计需要花费 9 分钟才能阅读完成。
环境:SLES11 SP4 + Oracle 11.2.0.4
新搭建测试数据库,跑了两天左右发现一个名为 kswapd0 的进程竟然占用了 1 个 cpu 资源 (该主机一共只有 2 个 cpu),而且几乎都耗在 cpusys 上。
如下图所示:
图 1
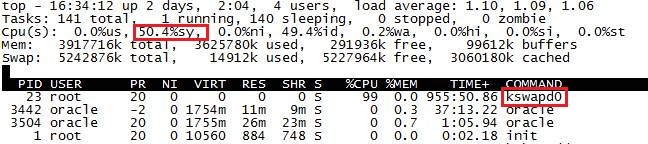
网上搜索得知 kswapd0 是一个内核进程,用来处理页的交换,当 OS 的可用内存小于阀值时,kswapd 会将部分进程的页从物理内存交换到 swap 上,这个阀值如何确定,颇费周折的找寻了一番仍然没有结果,至少在 SLES 11 这个版本下打消了我通过修改阀值来阻止 kswapd0 进程过渡活跃地消耗 cpusys 的解决思路。
从数据库层面入手,首先检查 SGA 是否被 lock 在了内存里
SQL> show parameter lock_sga
NAME TYPE VALUE
———————————— ———————- ——————————
lock_sga boolean TRUE
SQL>
OS 层面再 double check 一下,确实 lock 住了
oracle@cspdb1:~> ipcs -m
—— Shared Memory Segments ——–
key shmid owner perms bytes nattch status
0x00000000 196611 oracle 640 16777216 29 locked <– 确实 lock 住了
0x00000000 229380 oracle 640 1560281088 29 locked
0xf8e2566c 262149 oracle 640 2097152 29 locked
OS 层面检查物理内存尚有空闲,而真正的 swap 动作发生的次数并不多,不然应用早就来投诉了
图 4 
图 5 
从上述检查结果我们初步可以判断: 数据库的 SGA 确被锁定在了物理内存里,kswapd0 虽然辛勤劳作 (占去了一个 cpu 资源) 但产出却很少(被 swap 出来的页很少)
该服务器上除了 oracle db 外,并没有其它应用,db 上的会话数也只有几十个,因此最大的内存空间还是 SGA,想起之前曾经在 AIX 上启用过大内存页,最大的好处当然是提供更大 size 的连续页块,减少页表在内存里的占用空间,加快页表的搜索速度,还有一个好处就是大内存页永远不会被 swap out
为排除 SGA 可能会被换出物理内存或者至少避免 kswapd0 进程对 SGA 区域进行的无谓扫描来检测是否有能被 swap out 的页,我们按照如下步骤启用大内存页
###1、设定 /etc/security/limits.conf 以及设定后的检查
* soft memlock unlimited
* hard memlock unlimited
— 以 oracle 登录主机运行检查上述设定是否生效
oracle@cspdb1:~> ulimit -Hl
unlimited
oracle@cspdb1:~> ulimit -Sl
unlimited
###2、确认没有启用 AMM,因为 AMM 和 lock_sga 不兼容
set linesize 100
col name format a30
col value format a30
select name,value from v$system_parameter where name in (‘memory_target’,’memory_max_target’,’lock_sga’);
NAME VALUE
—————————— ——————————
lock_sga TRUE
memory_target 0
memory_max_target 0
— 如果 AMM 参数或者 lock_sga 设置不符合要求,可以按照如下步骤重设
SQL> alter system reset memory_max_target;
SQL> alter system reset memory_target;
SQL> alter system set lock_sga=true scope=spfile;
###3、设置大内存页
— 计算大内存页的数量,注意执行这一步的时候必须保证实例至少启动到 nomount 状态
oracle@cspdb1:~> ipcs -m
—— Shared Memory Segments ——–
key shmid owner perms bytes nattch status
0x00000000 196611 oracle 640 16777216 29 locked
0x00000000 229380 oracle 640 1560281088 29 locked
0xf8e2566c 262149 oracle 640 2097152 29 locked
oracle@cspdb1:~> cat /proc/meminfo | grep Hugepagesize
Hugepagesize: 2048 kB
最终需要的 hugepages=(16777216/2048/1024+1)+(1560281088/2048/1024+1)+(2097152/2048/1024+1)=756
— 在 /etc/sysctl.conf 里加入
vm.nr_hugepages=756
###4、重启数据库实例与主机,检查大内存页设置是否生效
sqlplus ‘/as sysdba’
shutdown immediate
init 6
cspdb1:~ # sysctl -n vm.nr_hugepages
756
oracle@cspdb1:~> grep HugePages /proc/meminfo
AnonHugePages: 45056 kB
HugePages_Total: 756
HugePages_Free: 756
HugePages_Rsvd: 0
HugePages_Surp: 0
startup
oracle@cspdb1:~> ipcs -m
—— Shared Memory Segments ——–
key shmid owner perms bytes nattch status
0x00000000 196611 oracle 640 16777216 27 <— 状态从 locked 变为空值了,说明大页天生不会被 swapout,所以不 care lock_sga 的设置:)
0x00000000 229380 oracle 640 1560281088 27
0xf8e2566c 262149 oracle 640 2097152 27
cspdb1:~ # grep HugePages /proc/meminfo
AnonHugePages: 67584 kB
HugePages_Total: 756
HugePages_Free: 623 <—Free < Total,说明已经有 huge page 被使用了
HugePages_Rsvd: 620
HugePages_Surp: 0
过去一周了 kswapd0 进程没有再冒泡上来,详见下图
图 6 
以下是我对这个现象原因的猜测:当 SGA 以普通页的形式存在于内存中的时候,虽然 lock_sga=TRUE,但仍然无法阻止 kswapd0 进程对于 sga 内存区域的不断扫描当然结果是不会有 page 会被 swap out,因为 lock_sga=TRUE。但这一过程中存在较多的内核级调用所以 kswapd0 进程会占用大量的 cpusys 资源。所以彻底的方法就是启用大内存页。
本文永久更新链接地址:http://www.linuxidc.com/Linux/2016-07/133124.htm













