")

共计 11030 个字符,预计需要花费 28 分钟才能阅读完成。
本文参考 MySQL 官方文档,算法书籍,部分为自己观点可能有误, 如果有误请指出共同讨论
一、MySQL 排序可能用到的排序算法
从 MySQL 官方文档和源码的接口来看 MySQL 使用 BUFFER 内部快速排序算法,外部多路归并排序算法,相应的接口函数为 filesort()函数,注意 filesort()是一个总的接口,内部排序实际调用 save_index()下的 std::stable_sort\std::sort、 归并排序也包含在下面接口可能为 merge_many_buff(),也就像执行计划中 using filesort 的含义,他只能代表使用了排序,但是是否使用到 tempfile 排序是看不出来的,但是这个可以再 trace 看到但是线上是不可以 trace 的研究是可以的,随后我会演示。
还要注意 using temporary 只是说明使用了临时表存储中间结果,这里先不讨论,只看排序。
下面简要介绍两种算法原理
1、buffer 内部 快速排序算法
快速排序是交换排序类算法,是冒泡排序的升级版,其原理是采用分而治之的思想,在于每趟交换设置一个基准点,将大于这个基准点的数据放到一边,大于的放到另一边,不断的进行递归完成,对于大数据量的排序快速排序一般效率优秀,在文章的最后是一个简单的快速排序的实现,如果对算法感兴趣的可以参考一下。但是至少还能进行 3 种优化
– 小数据优化,因为快速排序对数据量小的时候并不是最优,可以使用其他排序算法如插入排序。
– 尾递归优化,减少栈的使用
– 基准点优化,尽量取到数据中的中间值作为基准点,这样能够让快速排序更加优化。
2、外部磁盘多路归并排序
将内部快速排序后有序的数据文件进行不断的比较得到有序的文件,每次归并多少个文件就是归并的路数
图中每一个 R 当然代表的一个有序的磁盘文件
下图 2 路归并排序(截取数据结构 C 语言版)

下图 5 路归并排序 ( 截取数据结构 C 语言版)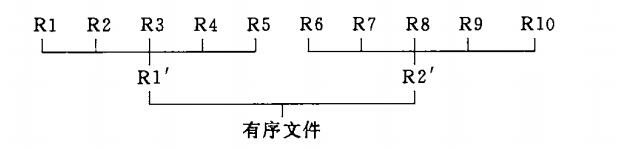
二、MYSQL 相关参数
sort_buffer_size:
当然也就是每次排序的 buffer,用作内部快速排序用,如果 buffer 越大当然产生的物理文件也就越少,但是这个参数是会话级别的,过分加大会造成内存不足,默认 256K。注意:
On Linux, there are thresholds of 256KB and
2MB where larger values may significantly slow down memory allocation, so you should consider staying
below one of those values
read_rnd_buffer_size:
除了 MRR 用到,这里也用到了用于 二次排序的时候对排序好的数据按照 primary key(ROW_ID) 按照分块的方式再次排序,意义同样在回表取数据可以尽量顺序化
max_length_for_sort_data:
单位为字节(bytes),如果排序返回行的字段长度综合大约这个值,使用二次排序而不是一次排序,默认 1024,最小值为 4,如果加大这个值可能过多的使用一次排序造成高 TEMPFILE 空间使用而 CPU 不高, 为什么如此后面解释。
max_sort_length:
单位为字节(bytes),如果排序字段的长度超过这个值,只是用这个参数设置的长度,默认 1024,比如 text 这种字段经常会大于这个值,如果加大这个值明显会提高排序的准确性,但是也意味着更高的 BUFFER 使用和 TEMPFILE 使用
三、监控磁盘排序
Sort_merge_passes:磁盘排序归并次数,减少 sort_buffer_size 大小会显著减少 Sort_merge_passes 值,并且临时文件也会变少,第五部分证明
sys.statements_with_sorting 视图
四、MYSQL 二次访问排序 (original method) 和一次访问排序(modified method)
1、二次访问排序
– 读取数据只包含排序键值和 rowid(primary key) 放到 sort buffer
– 在 buffer 中进行快速排序,如果 buffer 满则把内存中的排序数据写入 tempfile
– 重复上面的过程直到内部快速排序完成,并且生成多个 tmepfile 文件
– 进行多路归并排序源码接口在 merge_many_buff(),其中定义了 MERGEBUFF,MERGEBUFF2 2 个宏
这个在官方文档上有出现所以提出来说明一下
/* Defines used by filesort and uniques */
#define MERGEBUFF 7
#define MERGEBUFF2 15
如果有兴趣的可以仔细看看源码..
– 最后一次归并的时候,只有 rowid(priamry key) 到最后的文件中
– 对最后的文件根据 rowid(primary key) 访问表数据,这样就可以得到排序好的数据
这里有一个类似 MRR 的优化,将数据进行分块读入 read_rnd_buffer_size 进行
按照 rowid(primary key) 排序在去访问表的数据,目的在于减少随机读取造成的影响, 但是这是分块的,只能减少不能杜绝,特别是数据量特别大的情况下,因为 read_rnd_buffer_size 只有默认 256K.
问题在于对表数据的二次访问,一次在读取数据的时候,后一次在通过排序好的 rowid(primary key)进行数据的访问,并且会出现大量随机访问。
2、一次访问排序
这个就简单了,二次访问排序是把排序键值和 rowid(primary key)放到 sort buffer,这个就是关于需要的数据字段全部放到 sort buffer 比如:
select id,name1,name2 from test order by id;
这里 id,name1,name2 都会存放到 sort buffer 中。这样排序好就好了,不需要回表取数据了,当然这样做的劣势就是更大的 sort buffer 占用,更大 tempfile 占用。所以 mysql 使用 max_length_for_sort_data 来限制默认 1024,这是指 id,name1,name2 字段的 bytes 长度。
因为不需要回表,所以只要一次访问数据
3、5.7.3 后一次访问排序算法的优化
使用一个叫做 pack 优化的方法,目的在于压缩 NULL 减少一次访问排序算法对 sort buffer 和 tempfile 的过多使用
原文:
without packing, a VARCHAR(255)
column value containing only 3 characters takes 255 characters in the sort buffer. With packing,
the value requires only 3 characters plus a two-byte length indicator. NULL values require only
a bitmask.
但是我在做 MYSQL TRACE 的时候发现这还有一个 unpack 的过程,并且每一行每一个字段都需要 pack unpack
随后证明
关于使用了的那种排序方式在执行计划中都体现为 filesort 不好弄清楚,但是我们可以通过 trace 的方式,在官方文档也说了,但是我使用了对 MYSQLD 的 trace 方式来做,效果一致,详细参考第五部分
五、证明观点
1、首先需要证明是使用的是二次访问排序还是一次访问排序,是否启用了 pack
官方文档说明
“filesort_summary”: {
“rows”: 100,
“examined_rows”: 100,
“number_of_tmp_files”: 0,
“sort_buffer_size”: 25192,
“sort_mode”: “”
}
sort_mode:
: This indicates use of the original algorithm.
: This indicates use of the modified algorithm.
: This indicates use of the modified algorithm. Sort
buffer tuples contain the sort key value and packed columns referenced by the query.
也就是说
sort_key, rowid 是二次访问排序
sort_key, additional_fields 是一次访问排序
sort_key, packed_additional_fields 是一次访问排序 +pack 方式
好了我们来证明,使用测试表
mysql> show create table testmer \G;
*************************** 1. row ***************************
Table: testmer
Create Table: CREATE TABLE `testmer` (
`seq` int(11) NOT NULL,
`id1` int(11) DEFAULT NULL,
`id2` int(11) DEFAULT NULL,
`id3` int(11) DEFAULT NULL,
`id4` int(11) DEFAULT NULL,
PRIMARY KEY (`seq`),
KEY `id1` (`id1`,`id2`),
KEY `id3` (`id3`,`id4`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.01 sec)
mysql> select * from testmer ;
+—–+——+——+——+——+
| seq | id1 | id2 | id3 | id4 |
+—–+——+——+——+——+
| 1 | 1 | 2 | 4 | 4 |
| 2 | 1 | 3 | 4 | 5 |
| 3 | 1 | 2 | 4 | 4 |
| 4 | 2 | 4 | 5 | 6 |
| 5 | 2 | 6 | 5 | 8 |
| 6 | 2 | 10 | 5 | 3 |
| 7 | 4 | 5 | 8 | 10 |
| 8 | 0 | 1 | 3 | 4 |
+—–+——+——+——+——+
8 rows in set (0.01 sec)
分别在 max_length_for_sort_data 为 1024 和 max_length_for_sort_data 为 4 对
select * from testmer order by id1;
生成 trace 文件
意义也就是使用一次访问排序和二次访问排序, 因为数据量少也就在 sort_buffer
排序就好了。
一次访问排序:
opt: filesort_execution: ending struct
opt: filesort_summary: starting struct
opt: rows: 8
opt: examined_rows: 8
opt: number_of_tmp_files: 0
opt: sort_buffer_size: 34440
opt: sort_mode: “”
opt: filesort_summary: ending struct
为 一次访问排序 +pack 方式
二次访问排序���
opt: filesort_execution: ending struct
opt: filesort_summary: starting struct
opt: rows: 8
opt: examined_rows: 8
opt: number_of_tmp_files: 0
opt: sort_buffer_size: 18480
opt: sort_mode: “”
opt: filesort_summary: ending struct
为是二次访问排序
可以看到不同,证明了 max_length_for_sort_data 的作用
其实这个是 filesort()函数中的一个调用而已,其实 gdb 也可以打上断点也能看到
Opt_trace_object(trace, “filesort_summary”)
.add(“rows”, num_rows)
.add(“examined_rows”, param.examined_rows)
.add(“number_of_tmp_files”, num_chunks)
.add(“sort_buffer_size”, table_sort.sort_buffer_size())
.add_alnum(“sort_mode”,
param.using_packed_addons() ?
“” :
param.using_addon_fields() ?
“” : “”);
2、证明减少 sort_buffer_size 大小会显著减少 Sort_merge_passes 值,并且临时文件也会变少
为了完成这个证明我建立了一个大表,降低先 sort_buffer 为使用如下的语句使用更多的
tempfile 进行排序
mysql> select count(*) from testshared3;
+———-+
| count(*) |
+———-+
| 1048576 |
+———-+
1 row in set (28.31 sec)
mysql> set sort_buffer_size=50000;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like ‘%sort_buffer_size%’;
+————————-+———+
| Variable_name | Value |
+————————-+———+
| sort_buffer_size | 50000 |
+————————-+———+
mysql> show status like ‘%Sort_merge%’;
+——————-+——-+
| Variable_name | Value |
+——————-+——-+
| Sort_merge_passes | 0 |
+——————-+——-+
1 row in set (0.00 sec)
mysql> explain select * from testshared3 order by id limit 1048570,1;
+—-+————-+————-+————+——+—————+——+———+——+———+———-+—————-+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+—-+————-+————-+————+——+—————+——+———+——+———+———-+—————-+
| 1 | SIMPLE | testshared3 | NULL | ALL | NULL | NULL | NULL | NULL | 1023820 | 100.00 | Using filesort |
+—-+————-+————-+————+——+—————+——+———+——+———+———-+—————-+
mysql> select * from testshared3 order by id limit 1048570,1;
+——+
| id |
+——+
| 1 |
+——+
1 row in set (5 min 4.76 sec)
完成后
mysql> show status like ‘%Sort_merge%’;
+——————-+——-+
| Variable_name | Value |
+——————-+——-+
| Sort_merge_passes | 63 |
+——————-+——-+
1 row in set (0.21 sec)
opt: number_of_tmp_files: 378
临时文件数量 378
然后加大 sort_buffer_size
mysql> show variables like ‘%sort_buffer_size%’;
+————————-+———+
| Variable_name | Value |
+————————-+———+
| sort_buffer_size | 262144 |
+————————-+———+
mysql> show status like ‘%Sort_merge%’;
+——————-+——-+
| Variable_name | Value |
+——————-+——-+
| Sort_merge_passes | 0 |
+——————-+——-+
1 row in set (0.04 sec)
还是同样的语句
mysql> select * from testshared3 order by id limit 1048570,1;
+——+
| id |
+——+
| 1 |
+——+
1 row in set (5 min 4.76 sec)
mysql> show status like ‘%Sort_merge%’;
+——————-+——-+
| Variable_name | Value |
+——————-+——-+
| Sort_merge_passes | 11 |
+——————-+——-+
opt: number_of_tmp_files: 73
临时文件数量 73
得到证明
3、证明有 pack 和 unpack 操作,并且每一行每一个字段都需要 pack unpack
这个直接查看 trace 文件是否有接口就好了
实际上可以看到 8 段如下的操作
>Field::unpack
Field::unpack
Field::unpack
Field::unpack
Field::unpack
Field::unpack
Field::unpack”|wc -l
40
[root@testmy tmp]# cat sortys2.trace|grep “>Field::pack”|wc -l
40
刚好是 5(字段)*8(行)
当然我随后对一个大表只有一个字段的表进行一样的测试,既然是一个字段使用一次访问排序的时候排序的全部字段就是这个字段而已,所以 pack 和 unpack 的次数应该和行数差不多
mysql> select count(*) from testshared3;
+———-+
| count(*) |
+———-+
| 1048576 |
+———-+
1 row in set (28.31 sec)
mysql> desc testshared3;
+——-+———+——+—–+———+——-+
| Field | Type | Null | Key | Default | Extra |
+——-+———+——+—–+———+——-+
| id | int(11) | YES | | NULL | |
+——-+———+——+—–+———+——-+
1 row in set (0.26 sec)
[root@testmy tmp]# cat mysqld11.trace|grep “>Field::unpack”|wc -l
1048571
也得到同样基本相同的结构,证明了一次访问排序中每一行每一个字段都需要 pack、unpack 操作,其实在整个 trace 中还能看到很多类容比如列取出了
一次访问排序的全部字段,这里就不在详解了
六、源码 GDB 发现内部排序调用 STD 容器的 std::stable_sort std::sort 进行排序
(gdb) n
250 if (param->sort_length < 10)
(gdb) list
245 than quicksort seems to be somewhere around 10 to 40 records.
246 So we’re a bit conservative, and stay with quicksort up to 100 records.
247 */
248 if (count <= 100)
249 {
250 if (param->sort_length < 10)
251 {
252 std::sort(m_sort_keys, m_sort_keys + count,
253 Mem_compare(param->sort_length));
254 return;
这部分 mysql 上的源码
/*
std::stable_sort has some extra overhead in allocating the temp buffer,
which takes some time. The cutover point where it starts to get faster
than quicksort seems to be somewhere around 10 to 40 records.
So we’re a bit conservative, and stay with quicksort up to 100 records.
*/
if (count <= 100)
{
if (param->sort_length < 10)
{
std::sort(m_sort_keys, m_sort_keys + count,
Mem_compare(param->sort_length));
return;
}
std::sort(m_sort_keys, m_sort_keys + count,
Mem_compare_longkey(param->sort_length));
return;
}
// Heuristics here: avoid function overhead call for short keys.
if (param->sort_length < 10)
{
std::stable_sort(m_sort_keys, m_sort_keys + count,
Mem_compare(param->sort_length));
return;
}
std::stable_sort(m_sort_keys, m_sort_keys + count,
Mem_compare_longkey(param->sort_length));
最后附上快速排序的代码
带排序数据是 13,3,2,9,34,5,102,90,20,2
排序完成后如下:
gaopeng@bogon:~/datas$ ./a.out
sort result:2 2 3 5 9 13 20 34 90 102
/*************************************************************************
> File Name: qsort.c
> Author: gaopeng QQ:22389860
> Mail: gaopp_200217@163.com
> Created Time: Fri 06 Jan 2017 03:04:08 AM CST
************************************************************************/
#include<stdio.h>
#include<stdlib.h>
int partition(int *k,int low,int high)
{
int point;
point = k[low]; // 基准点, 采用数组的第一个值,这里实际可以优化
while(low<high) // 等待 low=high 一趟交换完成
{
while(low<high && k[high] >=point) // 过滤掉尾部大于基准点的值, 不需要交换
{
high–;
}
k[low] = k[high]; // 基准点多次交换为无谓交换直接赋值即可
while(low<high && k[low] <=point) // 过滤掉头部小于基准点的值, 不需要交换
{
low++;
}
k[high] = k[low]; // 基准点多次交换为无谓交换直接赋值即可
}
k[low] = point;
return low;
}
int q_sort(int *k,int low,int high)
{
int point;
if(low<high)
{
point = partition(k,low,high);
q_sort(k,low,point-1); // 实现递归前半部分
q_sort(k,point+1,high); // 实现递归后半部分
}
return 0;
}
int main()
{
int i,a[10]={13,3,2,9,34,5,102,90,20,2}; // 测试数据
q_sort(a,0,9); // 数组下标 0 9
printf(“sort result:”);
for(i=0;i<10;i++)
{
printf(“%d “,a[i]);
}
printf(“\n”);
}
本文永久更新链接地址:http://www.linuxidc.com/Linux/2016-12/138493.htm














